library(tidyverse)
library(readxl)
library(tidytext)
library(widyr)Indeksering gennem netværksanalyse
Resultatet af vores tekstgenkendelse og segmentering var en tekstmængde, der var så stor, at det ikke var realistisk for os at indeksere artiklerne med udgangspunkt i manuel kategorisering. Samtidig ønskede vi, at projektet skulle udforske metoder, der kan skaleres til endnu større tekstmængder. Vi var ikke tilfredse med blot at gøre arkivet søgbart - vi ønskede også at skabe andre pejlinger, hvormed brugere kunne navigere arkivet, herunder udforske slægtskab imellem dets tekster. Vi håbede på, at denne proces kunne muliggøre identifikationen af typer af tekster eller sågar et form for emneindeks.
I første af en række forsøg i denne retning benyttede vi netværksvisualisering og bearbejdning som en vej til at finde beslægtede klynger af ord. Med afsæt i sådanne klynger søgte vi at identificere at definere, hvorvidt en tekst er præget af bestemte emner. Dette workflow er beskrevet i denne artikel og involverer bearbejdning af vores data i R og i netværksvisualiseringsværktøjet Gephi. Resultatet kan ses som del af vores indeksering i vores søgeinterface. Bearbejdningen var samtidig et eksperiment i en form for fjern læsning af datasættet som en helhed. Et forsøg på at muliggøre en fornemmelse for avisens topologi gennem visualisering.
Bearbejdning i R
Første trin af bearbejdning foregik i R. Målet med denne procedure var at transformere vores segmenterede tekstdata til en graf - ikke i første omgang forstået som en visualisering, men som en datastruktur over relationer. Denne struktur består af lister over hhv. punkter og forbindelser og kan eksporteres til videre bearbejdning i Gephi. Koden er beskrevet nedenfor:
Vi starter med at loade de pakker, vi skal bruge.
Herefter importerer vi data og stopord og tilpasser datasættet ved at fjerne overskrifter.
df <- read_csv2("data/mod/df.csv") # Vi importerer data
stopord <- read_excel("data/mod/stopord.xlsx") # Vi importerer vores manuelt skabte stoprodsliste
df <- df %>%
filter(type != "overskrift") # vi vil ikke se på overskrifter i denne kontekst, så vi filtrerer dem fra.Herefter skaber vi grafen. Dette gøres med kodestykket nedenfor. Simpelt forklaret laver vi to udregninger: en der tæller, hvor mange gange to ord optræder i samme tekst, og en, der udregner pointwise mutual information (pmi). Sidstnævnte score fortæller, hvorvidt et ords tilstedeværelse medfører en større eller mindre sandsynlighed for, at et andet ord optræder. I processen filtrerer vi forinden tal, stopord og sjældne ord fra. Sjældne ord definerer vi som ord, der optræder færre end 40 gange i vores tekstkorpus. Stopordslisten skabte vi manuelt og opdaterede flere gange undervejs. Til sidst filtrerer vi vores ord således, at vi kun inkluderer de 100.000 højeste pmi-scorer. På den måde definerer vi en tærskel for, hvad der tæller som en forbindelse. Denne er åbenlyst ganske arbitrær. Senere filtrerer vi yderligere på samme parameter i Gephi, så denne indledende filtrering på pmi handler primært om, at skabe en grafstruktur, der ikke er alt for stor - og som vores computerer kan håndtere, når den bearbejdes visuelt.
I processen splittes vores data i hhv. “node table” og “edge table” - tabeller over henholdsvis punkter og forbindelser. Til punkterne knyttes en simpel optælling over, hvor mange gange enkelte ord optræder i materialet.
Her ses hvert skridt i en kommenteret version:
Token_df <- df %>%
rownames_to_column(var = "ID") %>% # skaber et ID for hver tekst
unnest_tokens(word, tekst) %>% # tokeniserer på ordniveau
anti_join(stopord) %>% # filtrerer stopord fra
filter(!str_detect(word, "[0-9]+")) %>% # filtrerer tal fra
group_by(word) %>% # grupperer på ordniveau
filter(n() >= 40) %>%# filtrerer sjældne ord ud
ungroup()
Token_count <- Token_df %>%
count(word, sort = TRUE) # laver en optælling på hvert af de tilbageværende ord
df_pmi <- Token_df %>%
pairwise_pmi(word, ID) %>% # udregner pointwise mutual information imellem ord i tekster
mutate(ordpar = paste(item1, item2, sep = " ")) # skaber en nøgle i form af et ordpar
df_pmi$ppmi <- df_pmi$pmi
df_pmi$ppmi[df_pmi$ppmi < 0] <- 0 # laver pmi om til ppmi (positive pointwise mutual information") ved at fjerne negative værdier.
df_pairwise_count <- Token_df %>%
pairwise_count(word, ID) %>% # vi laver en parvis optælling af ords optræden i tekster
mutate(ordpar = paste(item1, item2, sep = " ")) # skaber samme nøgle som ovenfor
edge_table <- df_pairwise_count %>% # vi skaber den endelige tabel over forbindelser
filter(n > 5) %>% # vi definerer et minimum for, hvornår noget er forbundet
left_join(select(df_pmi, ordpar, ppmi)) %>% # vi smelter vores to udregninger sammen
filter(item1 > item2) %>% # vi filtrerer dubletter væk
select(-ordpar) %>% # vi fjerner den nøgle, vi har brugt til at joine
rename(Source = item1,
Target = item2) %>% # vi omdøber kolonner, så de hedder det, Gephi forventer
slice_max(ppmi, n = 100000) # Vi definerer, at vi kun vil eksportere forbindelser med de højeste ppmi-scorer. Tallet definerer, hvor mange vi vil have med.
node_table <- Token_count %>% # Vi laver også en tabel over punkter.
rename(Id = word) # Og vi navngiver dens kolonner på en måde, så Gephi ved, hvad det er, vi importerer.Til sidst eksporterer vi henholdsvis punkter og forbindelser som csv-filer, der kan importeres direkte i Gephi.
write_csv(edge_table, "edge_table.csv")
write_csv(node_table, "node_table.csv")Bearbejdningen af grafen i Gephi
Gephi er designet til at bearbejde netværksgrafer med fokus på visualisering. Styrkerne ved visuel netværksanalyse er, at en visualisering af en graf kan læses på en intuitiv måde, hvor visualiseringens topografi af punkter kan tolkes med udgangspunkt i vores kontekstforståelse. Den tillader således en tilgang, der blander kvantitative og kvalitative læsninger. Samtidig gør teknikken det muligt at identificere tvetydigheder og sammenfiltringer i strukturer. Anders Kristian Munk og Tommasso Venturini har formuleret det således:
The strength of VNA comes from its capacity to conserve some of the ambiguity of the phenomena it represents. What are the frontiers of a group? Which nodes occupy the center of a community? Which edges bridge separated social regions? None of these questions has exact answers in social research and none is imposed by network visualizations.1
Vi importerede filerne i Gephi og bearbejdede herefter grafen yderligere ved at filtrere. Grundlæggende filtrede vi således, at vi kun visualiserede klynger af ord, der tilhørte den største sammenhængende klump. Desuden filtrede vi herefter på ppmi, så kun forbindelser med en score på 3 eller højere er inkluderet. I denne filtreringsproces forsvinder punkter og forbindelser, men et tydeligere mønster træder frem. Det kan på den måde tænkes som en form for kompromis eller kondensering, til fordel for en klarere forståelse for, hvad der kan tænkes som en grundlæggende struktur. Til sidst lavede vi yderligere en filtrering på såkaldt “degree” - en score, der kan udregnes i Gephi og fortæller, hvor mange forbindelser et givet punkt har. Rationalet her er at frasortere punkter med få forbindelser, igen for at få en klarere fornemmelse for strukturer i netværket.
Det er i vores øjne givende, at dette er en eksperimentel proces, hvor man prøver sig frem, indtil man ender med en visualisering, man selv vurderer fortæller noget. Denne struktur kan både illustrere noget, man forventede eller afsløre noget uventet. Der er ikke nødvendigvis nogen korrekt eller forkert fremgangsmåde, men man kan selvfølgelig ende med et resultat, der er filtreret på måder, man ikke selv kan gennemskue - hvorved risikoen for en fejltolkning stiger.
Da vi mente, at vi havde fundet en visuel form på vores graf, benyttede vi Gephis implementering af community detection med modularity classes. Denne non-deterministiske algoritme parcellerer grafen i grupper. Simpelt formuleret leder algoritmen efter grupper af punkter, der er mere forbundet internt end eksternt. Når den har fundet en sådan grænse, bevæger den sig videre og skaber en ny parcel, indtil der ikke er mere graf tilbage. Den starter et tilfældigt sted i grafen og hvert forsøg på community detection vil derfor generere et lidt andet udtryk, og antallet af grupper kan variere. Det kan af samme grund også her være nyttigt at eksperimentere.
Hvis du skulle være interesseret i selv at arbejde med grafen i Gephi, kan den downloades som .gephi her.
Manuel annotation
Da vi havde skabt vores visualisering printede vi den ud på papir. I små grupper kiggede vi på den og nærstuderede de enkelte klynger med henblik på at navngive dem. Vi kæmpede lidt med størrelsen, da vores printer ikke tillod at vi printede i formater større end a3. Så nogle skiftede frem og tilbage imellem skærm og papir. I processen spurgte vi os selv, hvad klyngerne handlede om? Nogle af dem var ganske tydeligt knyttet til bestemte genrer af annoncer, imens andre syntes at antyde nogle tematiske grupperinger. Nedenfor ses et eksempel af denne annoterede version.
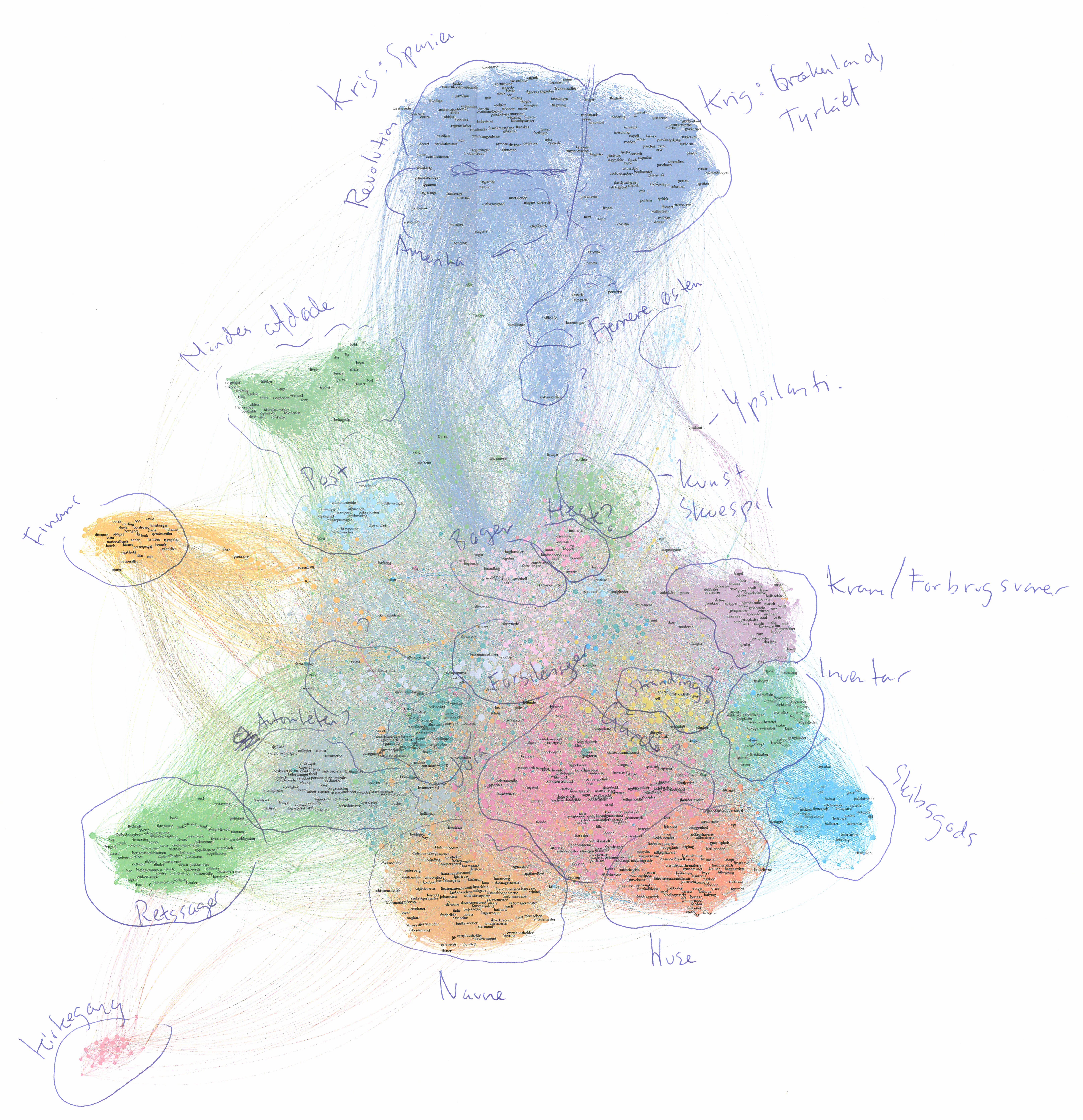
Bemærk at den annoterede version skete med en minimalt anden grad af filtrering, end ovenfor. Derfor har grafen et andet udtryk.
Til sidst eksporterede vi i Gephi vores liste med punkter - nu med ordenes tilhørsforhold til de visualiserede grupper. Med udgangspunkt i vores manuelle annotationer navngav vi således hver modularity class med termer, vi forestillede os ville være passende i konteksten af et indeks.
Indekseringen med udgangspunktet i modularity class
Det er i denne sammenhæng vigtigt at pointere, at de kategorier, vi dermed fik skabt, ikke opererer på samme niveau eller er bare tilnærmelsesvis lige store. F.eks. handler en af de identificerede modularity classes om heste og ord, der knytter sig dertil, imens en anden handler bredt om nyhedsstof. En tredje klynge er defineret af slægtskab ved at italesætte følelser, men knytter sig til en bred vifte af tekster - både nyhedsstof og annoncestof. På denne måde er kategoriseringen på et abstrakt plan dybt heterogen. Imidlertid reflekterer den nogle strukturer i materialet, der er tilpas klare til, at indekseringen i de fleste tilfælde er nogenlunde retvisende.
Nedenfor findes den kode, der med udgangspunkt i vores liste over ord identificerer, hvilke ordklynger, der definerer en artikel.
avis <- df %>%
rownames_to_column(var = "ID") # Vi skaber et id, så vi senere kan knytte kategoriseringen til den enkelte artikel.
ord_mod <- read_csv("data/mod/ord_modularities.csv") # Vi loader vores liste over ord og hvilke modularities, de tilhører.
df_tokens <- avis %>%
unnest_tokens(word, tekst) %>% # Vi tokeniserer teksterne på ordniveau...
left_join(ord_mod, by = c("word" = "Id")) # ... og binder modularity klasserne fra vores nodetable til ordene i artiklerne.
article_modularity <- df_tokens %>% # Vi udregner hvor mange ord fra hver ordklynge, hver artikel indeholder.
group_by(ID) %>% # først grupperer vi de tokeniserede ord efter ID
mutate(modularity_class = as.character(modularity_class)) %>% # vi laver modularity class kolonnen om til strings
count(modularity_class) %>% # så optæller vi hvor mange ord fra hver modularity class hver tekst indeholder
na.omit() %>% # vi fjerner na-værdier
group_by(ID) %>% # grupperer igen
slice_max(n) %>% # og vælger for hver artikel de rækker, der har flest ord.
ungroup()
avis_med_modularity <- avis %>%
left_join(article_modularity) %>% # vi joiner vores resultat tilbage på de oprindelige tekster vha. ID.
mutate(ord_antal = str_count(tekst, "\\w+"), # vi udregner et antal ord for hver tekst
mod_topic_ratio = n / ord_antal) %>% # og en ratio for hvor mange af de ord, er kommer fra det mest dominerende cluster
filter(mod_topic_ratio > 0.05) %>% # Vi definerer, at mindst 5% af ordene i en tekst skal være defineret af ord fra en bestemt klasse, hvis den skal kategoriseres med dette indeksord.
filter(n > 1)Resultatet kan udforskes i vores søgeinterface. Bemærk, at det er under halvdelen af de samlede tekster, der igennem denne bearbejdning får tildelt et indeksord. Det skyldes, at mange tekster ikke i tilstrækkelig grad er præget af ord fra disse ordklynger - fordi de er del af et strukturelt lag, der ikke afsløres gennem vores bearbejdning. På den måde finder vi gennem denne proces forslag til, hvor der findes strutkurer i materialet, men processen er på ingen måde udtømmende. Samtidig ignorerer vi det faktum, at en tekst sagtens kan handle om flere ting. Metoden skal dermed ikke tænkes som et facit, men som et forslag til en vej, hvorved arkivet kan navigeres.
Bemærk at vi undervejs i hele processen ændrede navnene på kategorier, når vi fik fornemmelse for, at vores oprindelige navngivning ikke var dækkende. På den måde var der også her tale om en iterativ proces. Enkelte kategorier endte vi med ikke at navngive, da de ikke syntes at antyde slægtskaber, der meningsfuldt kunne nytte i konteksten af en indeksering. Denne proces skete sideløbende med vores forsøg på at benytte topic modelling, der er beskrevet andetsteds her på siden.
Fodnoter
Anders Kristian Munk og Tomasso Venturini, Controversy Mapping: a field guide (Polity Press, 2022), s. 206.↩︎