Johan Heinsen, Louise Karoline Sort, Laura Marie Ahrensbach, Julie Edelsten, Alexander Simon Kjølby Carlsen, Andreas Winkler Bønnelykke, Adrian Ledaal Gundersen, Jonathan Eskerod Qvistorff Kanstrup, Sarah Lydia Blok Kloster, Mads Meldgaard Skibsted Kristensen, Magnus Østergaard Larsen, Hans Niklas Holmgaard Pedersen, Louise Emilie Pedersen, Lea Ruess, Maja Thorsø Rønn, Ditte Nørgaard Schrøder, Oliver Thomsen, Stinna Victoria Østergaard
Published
December 1, 2024
Denne side indeholder dokumentation for skabelsen af Extraordinaire Digitale Relationer. Vi vil give et indblik i den bearbejdning avisen har undergået for at blive søgbar via vores interface. Målet er, at andre kan gøre det efter med et andet korpus.
Layout og tekstgenkendelse
Samlingens udgangspunkt er i det Kongelige Biblioteks digitalisering af avismaterialet. Denne digitalisering er sket via en affotografering, mikrofilmning og efterfølgende scanning af mikrofilmen. Vi ved ikke, hvornår affotograferingen er sket. Materialet er tilgængeligt som billedfiler via online-arkivet LOAR. Før vi gik videre, konverterede vi alle billeder fra .jp2 til .jpg, men beholdt de oprindelige filnavne, da disse indeholder metadata i form af udgavens dato.
Avisen blev uploadet i Transkribus. Her brugte vi en upubliceret fields-model til identificere spaltestrukturen. Dette skridt var nødvendigt, fordi avisens spalter kun er adskilt af en smal streg. Ønsker du selv at bruge modellen, kan du kontakte os. Det var dog nødvendigt at gennemgå alle sider manuelt for at tjekke for fejl, især i form af overlappende tekstregioner.
Vi trænede herefter en tekstgenkendelsesmodel på et sample med 300 sider. Avisen indeholder enkelte tillæg på tysk. Disse blev identificeret, og tyske sider blev heller ikke inkluderet i modellens træningsmateriale. Enkelte andre sider blev frasorteret, f.eks. hvis de blot indeholdte tabeller. Det endelige træningsmateriale i modellen er derfor på 248 sider. Modellen har en CER (character error rate) på 0.58%. På løbende brødtekst giver dette en fuldt læsbar tekst. Enkelte ting har modellen dog vanskeligt ved. Det inkluderer førnævnte tabeller, marginalia, kapitaliserede navne og initialer. Den brugte model har model id 186489 og er tilgængelig under navnet Seventeenth Century Danish Newspapers.
Segmentering
Efter eksport af data fra transkribus trænede vi en segmenteringsalgoritme. Koden var bygget over skabelonen skabt i projektet Klart som blæk.1 Vi benyttede dog en random forest algoritme frem for naive bayes. Resultatet møntede sig på hver enkelt linje og forsøgte at forudsige om den løbende tekst kun segmenteret ved linjeskift skulle splittes før den enkelte linje. Målet var at få en så korrekt segmentering i egentlig tekster som muligt. Den endelige algoritme havde en præcision på omkring 97%. Den ramte næsten altid plet på de regulære nyhedsrubrikker, men producerede en del fejl på typer af tekster, der forekommer mindre hyppigt i avisen. Lister var især et problem, hvor modellen tenderede imod at atomisere lister og fortegnelser til mange separate tekster. Af samme grund endte vi med at gå store dele af modellens positive gæt igennem for at luge ud blandt falske positive forudsigelser. Der vil stadig forekomme enkelte fejlsegmenteringer. I processen forsøgte vi også at filtrere sidetal og anden marginalia ud af den løbende tekst.
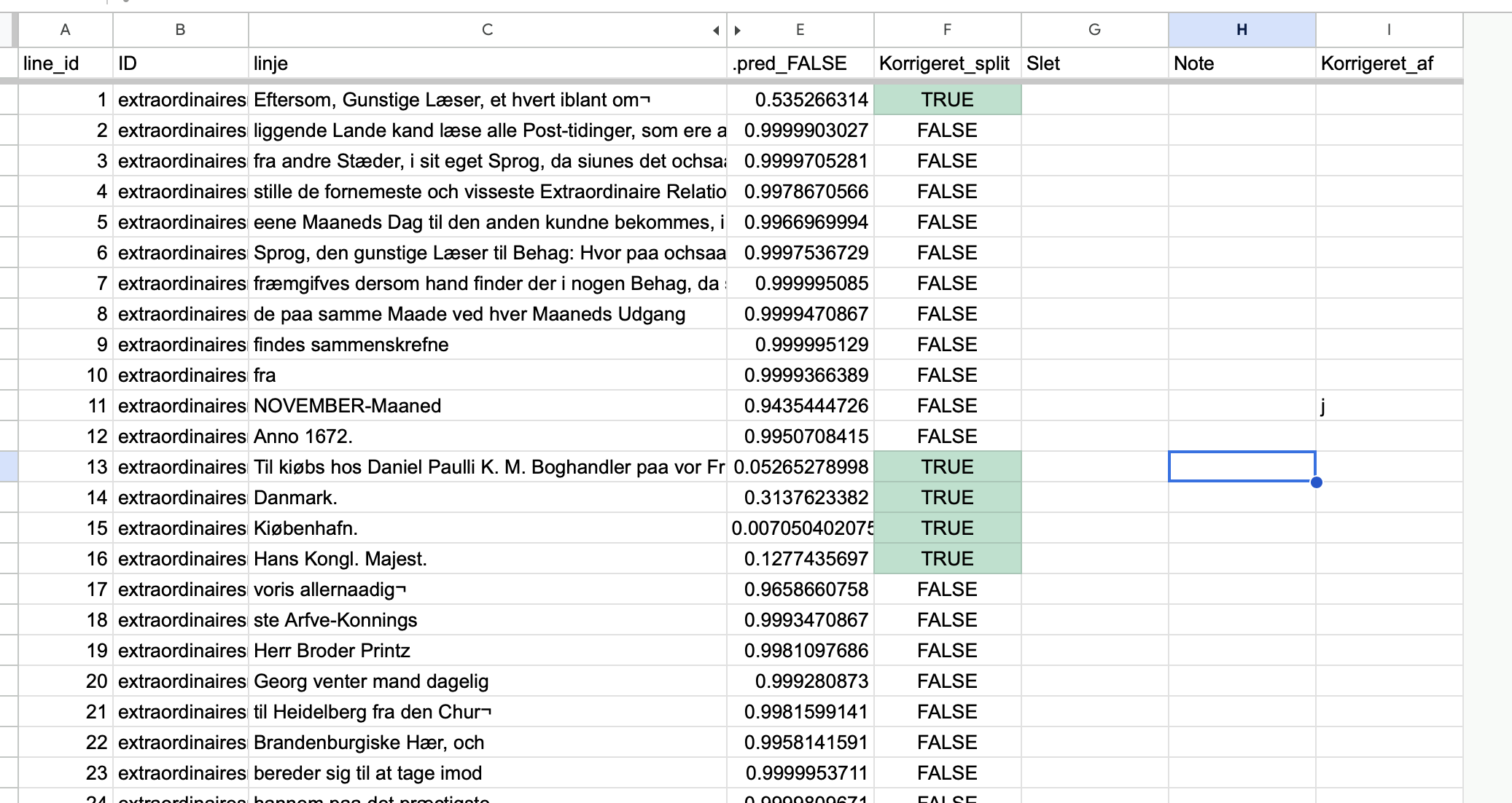
Resultatet er et datasæt i følgende format. Hver række er en linje identificeret i Transkribus. Datasættet indeholder ikke avisens tyske bilag.
Den bearbejdede segmentering
Næste skridt blev gjort i R. Det bestod i en bearbejdning af datasættet, der groft sagt samler linjer rundt om variablen “Korrigeret split”, således, at teksten splittes op, hver gang denne kolonne indeholder værdien TRUE. Samtidig filtreres der efter marginalia ved at lokalisere korte fragmenter på slutningen af hver side.
# A tibble: 6 × 5
# Groups: doc_id [6]
doc_id dato text ID count
<dbl> <chr> <chr> <chr> <int>
1 1000001 1672-11-01 Eftersom, Gunstige Læser, et hvert iblant omli… extr… 531
2 1000013 1672-11-01 Til kiøbs hos Daniel Paulli K. M. Boghandler p… extr… 70
3 1000014 1672-11-01 Danmark. extr… 8
4 1000015 1672-11-01 Kiøbenhafn. extr… 11
5 1000016 1672-11-01 Hans Kongl. Majest. voris allernaadigste Arfve… extr… 208
6 1000025 1672-11-01 Princessen af Zweybruch har her fra Hofve, hvo… extr… 109
Det bearbejdede datasæt indeholder dermed et id (doc_id), dato og den fulde tekst (text). Overskrifter fremstår som separate tekstbidder.
Links til Mediestream via KBs API
For at gøre det muligt for brugerne at se originalen implementerede vi et link tilbage til mediestream via KBs avis-api. Dette krævede en bearbejdning af datoen for at skabe et sidetal pr. udgave, og ikke alle tekster kunne matches med en side, men størstedelen af korpus kan følges til Mediestream, hvor det er muligt at se det originale scan.
# A tibble: 6 × 4
doc_id text dato kontekst
<dbl> <chr> <date> <chr>
1 1167936 Usædvanlig Veyrlig. 1698-05-01 " <a hr…
2 1167937 J denne Maaned har Frost, Snee og Kuld, saavel i … 1698-05-01 " <a hr…
3 1167951 Ulyckelige Hændelse. 1698-05-01 " <a hr…
4 1167952 Til Londen i Engelland er en fornemme Mand, ved N… 1698-05-01 " <a hr…
5 1167958 Til Strassborg er en fornemme Lottringiske Grefve… 1698-05-01 " <a hr…
6 1167965 J det Cleviske er en fornemme Person, ved Nafn Do… 1698-05-01 " <a hr…
Topic modelling
For at udforske materialet trænede vi en topic model på vores korpus. Modellen finder 20 emner baseret på de segmenterede tekster. Materialet filtreres i processen for stopord, som vi identificerede ved at kigge på de hyppigst forekommende termer i samlinger. Vi fulgte fremgangsmåden beskrevet af Julia Silge og David Robinson.
Warning in left_join(., top_docs, by = c(doc_id = "document")): Detected an unexpected many-to-many relationship between `x` and `y`.
ℹ Row 2903 of `x` matches multiple rows in `y`.
ℹ Row 10454 of `y` matches multiple rows in `x`.
ℹ If a many-to-many relationship is expected, set `relationship =
"many-to-many"` to silence this warning.
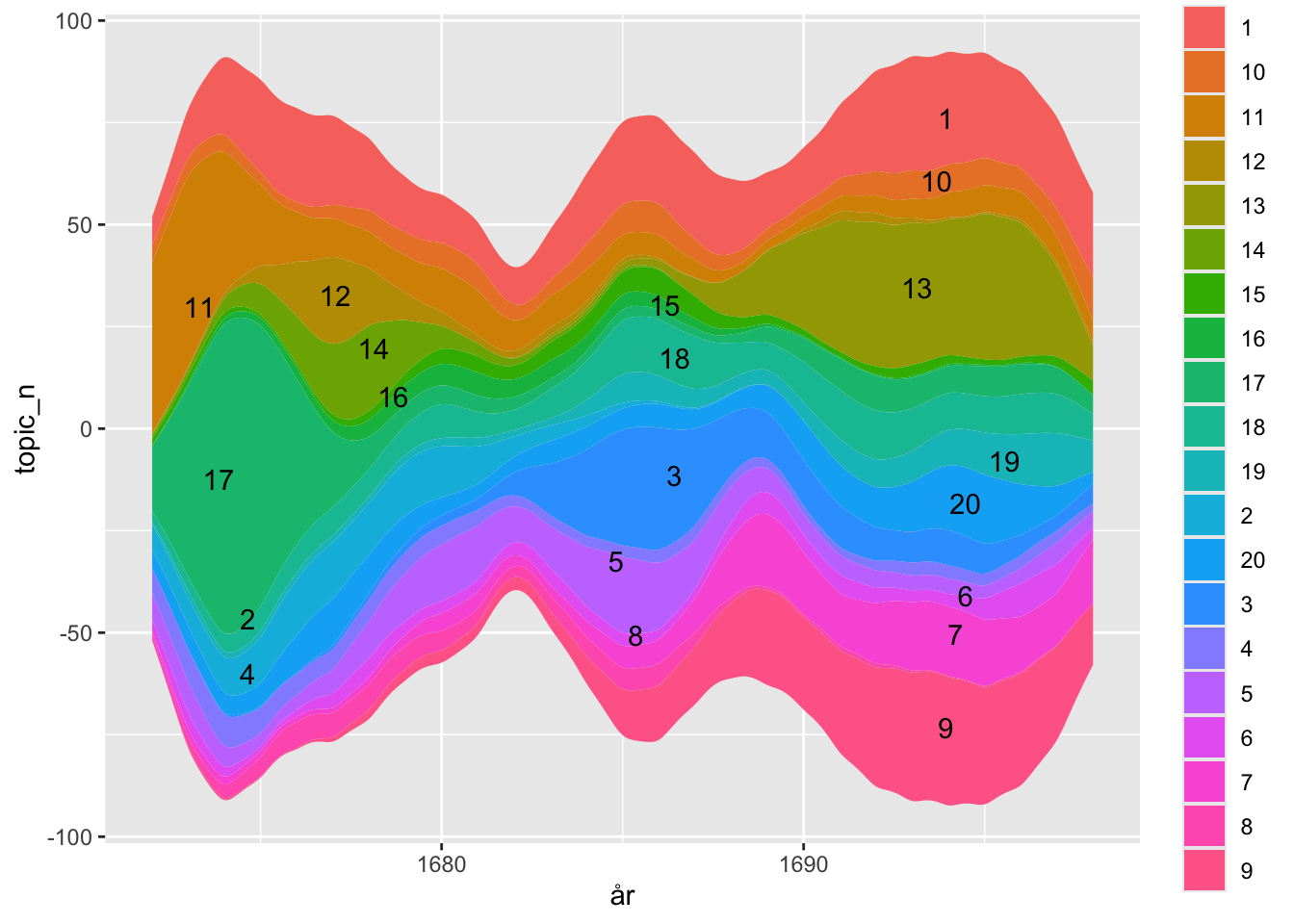
En spændende mønster er, at nogle topics knytter sig til bestemte perioder og geografier.
filter_docs <- top_gamma %>%mutate(år =year(dato)) %>%filter(gamma >0.8) %>%group_by(topic, år) %>%summarise(topic_n =n()) %>%pivot_wider(names_from = topic,values_from = topic_n,values_fill =0) %>%pivot_longer(cols =matches("\\d"),names_to ="topic",values_to ="topic_n")filter_docs %>%ggplot() +geom_stream(aes(x = år, y = topic_n, fill = topic)) +geom_stream_label(aes(x = år, y = topic_n, fill = topic, label = topic))
Vi gemte til sidst en version af vores datasæt, der matchede id med dets mest dominerende topic.
Med henblik på at udforske vores korpus trænede vi en word-embedding model. Vi bruge r-implemteringen af word2vec. Denne teknik træner statiske embeddings ved at forudsige kontekst med udgangspunkt i et givent ord. Teknikken virker bedst med mange millioner ord, hvilket vores samling ikke indeholder. Alligevel var de i mange tilfælde muligt at fange meningsfulde relationer imellem ord.
Med udgangspunkt i denne model trænede vi efterfølgende en embeddingmodel til teksterne. Forinden kollapsede vi korte tekster sammen med de efterfølgende tekster for at undgå at overskrifter i denne kontekst optræder som separate dokumenter. Vi lavede også en standardisering af dokumenterne for at mindske variation.
library(doc2vec)ord_vecs <-read.word2vec("data/skip150_hs_lr005_iter15_min_count3_window5.bin") ord_vecs_matrix <-as.matrix(ord_vecs) # Den skal laves til en matrixdf <-read_csv2("data/docs_link.csv") %>%mutate(doc_id =as.character(doc_id),str_n =str_count(text),ny_text =case_when(lag(str_n <30) ~paste(lag(text), text), .default = text)) %>%filter(str_n >30)df_standard <- df %>%mutate(text = ny_text) %>%select(doc_id, text) %>%mutate(text =tolower(text), # med småt for at give mindre variationtext =str_sub(text, 1, 5500), # kun de første 1000 ordtext =str_replace_all(text, "\\d+", ""), # vi fjerner taltext =str_replace_all(text, " \\.", "\\."), # vi fjerner " . "text =gsub("[[:space:]]+", " ", text), # vi fjerner gentagne mellemrumtext =trimws(text)) # vi fjerner mellemrum i starten eller slutningenmodel_1 <-paragraph2vec(df_standard,threads =6,hs =TRUE,iter =15,sample =0.001,dim =150,min_count =4,embeddings = ord_vecs_matrix)write.paragraph2vec(model_1, "data/extraordinaire_vecs_150.bin")
Dokumentvektoriseringen gør det blandt meget andet muligt at projicere nye sætninger ind i samlingens vektorrum og finde tekster, de dokumenter, der er nærmest.
sætning <-"der er fanget en merckelig fisk"sætning <-setNames(sætning, "1")sætning <-strsplit(sætning, split =" ")nærmeste <-predict(model_1,newdata = sætning,which ="sent2doc",type ="nearest",top_n =10)resultater <-as.data.frame(nærmeste) %>%left_join(df, by =c("X1.term2"="doc_id"))resultater$text[1:5]
[1] "Til Duyns i sidste Storm er en underlig Fisk fangen: Paa Skikkelsen lignede den en stoer Flynder, paa det flade under Bugen hafde den 2. Fødder med Tænder besatte, paa Ryggen 2 Finder lige som 2 Hænder; Hofvedet lignede et halft Menniske-Hofvet, samme Fisk døde strax och hæsligen stinkede."
[2] "Til Cadix har mand fanget en lefvendis Hauf-Mand, som ligner en ung Dreng paa 14. Aar, men er gandske dum och taler intet, och æder intet andet end Brød, som blødes i Vand: Samme Mareminde skal være i Don Antonii Esqvierdes. Enkes Huus at finde och see."
[3] "Fra Lands-Crone skrifvis at Bønderne ved Barsebeck hafver fanget en Fisk af Skickelse som en Større och hafde et Gevext som et stort Ris i Munden, och paa den venstre Side stod er W. Ofver Malmøe hafver sig ladet see adskillige Tegn, særdelis med Jld, som Byen paa mange Stæder hafde standen i Lue."
[4] "Den 3. Septembris blef en sælsom och underlig Fisk fanget, uden for Dragøe. For af Munden sad en lang Spitz som et Sverd. Rumpen var som paa en Helleflynder. Paa Ryggen stod en høy och lang Spitz som en Vinge. Ved Gellerne vare langactige Finder som i andre Fiske. Øynene vare saa store, som en temmelig Pomerantz. Och var den gandske Fisk halffierde Alen lang, och hafde ingen Been i sig uden Raden eller Rygbeenet. En anden af samme slag blef den 2. dito fanget i Bucten ved Roskild, men var halfanden Alen langere. De vare begge hvide i Kiødet, och allevegne inden for Huden omgifne med to Finger tyck Fet eller Flesk. Kiødet smagede som af en Lax, den minste blef lefveret til Forvalteren ofver Hans Kongl. Mayt. Kunst-KammerBendicht Grotschilling at hand skulde lade tage Huden deraf, och indføre den paa Kunst-Kammeret. De blefve och afridsede, och var Gestalten hart ad som følger. Gesnerus i hans vitløftige Skrift om Fiske siunis at regne dette slag blant Sverd-Fiske."
[5] "Ved Utrecht er paa nogle Ugers Tjd fanget saa stor en Mængde af smaa Gedder, som ere ikkun en Spande lange, saa det er fast utroligt. Anno 1574. skeede det ligesaa sammestæds med Karper."
Dimensionalitetsreduktion med UMAP
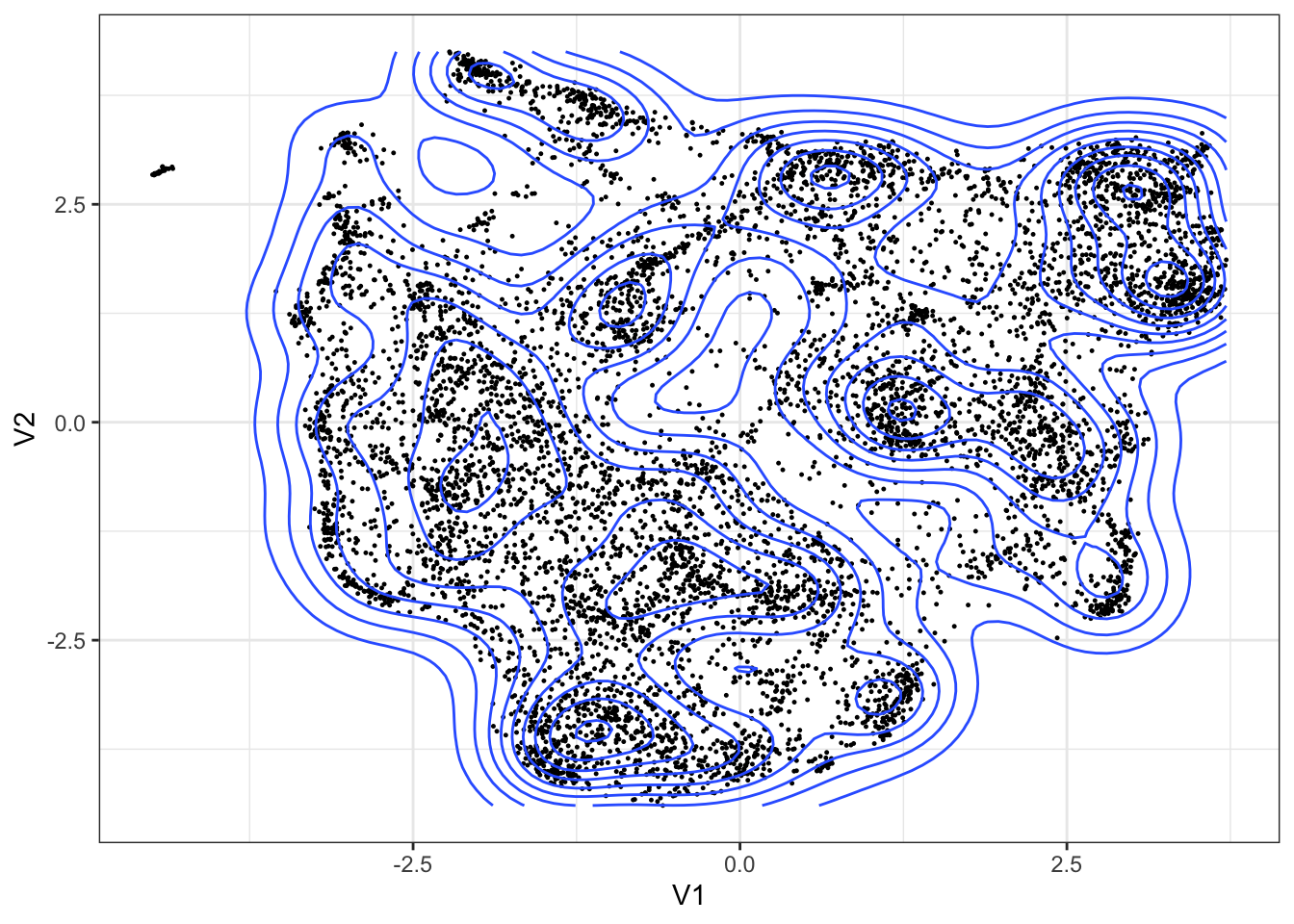
Med henblik på at visualisere korpus som en form for topgrafi reducerede vi vores dokument embeddings fra 150 til 2 dimensioner via UMAP (Uniform Manifold Approximation and Projection). Resultatet kan tænkes som en form for betydningskort, der fortæller om fortætninger i materialet rundt om bestemte punkter i vektorrummet. Tekster projiceres således ind i en geografi, hvor deres nærhed til andre dokumenter i mange tilfælde fortæller om slægtskab (af den ene eller anden art). Vi mener, at dette giver mulighed for at udforske kontekster, kontraster og overgange i materialet - og repræsenterer en vej ud af de faldgruber historikere ofte har associeret med keyword-søgning, nemlig at man dermed ikke får fornemmelse for materialets stoflighed ved at læse rundt om det man leder efter.2
library(umap)doc_matrix <-as.matrix(model_1, type ="docs") # vi skal bruge dokumenteres embeddings som en matrixumap_resultater <-umap(doc_matrix, n_neighbors =25,metric ="cosine") # vi træner vores umap-modelumap_koordinater <- umap_resultater$layout %>%as.data.frame() %>%rownames_to_column(var ="doc_id") %>%left_join(df) # vi henter dokumenternes koordinater ud af umap-modellen og joiner teksten tilbage via doc_id.write_csv2(umap_koordinater, "data/umap_koordinater.csv")ggplot(umap_koordinater) +geom_point(aes(x = V1, y = V2), size =0.2) +geom_density2d(aes(x = V1, y = V2), bins =10) +theme_bw()
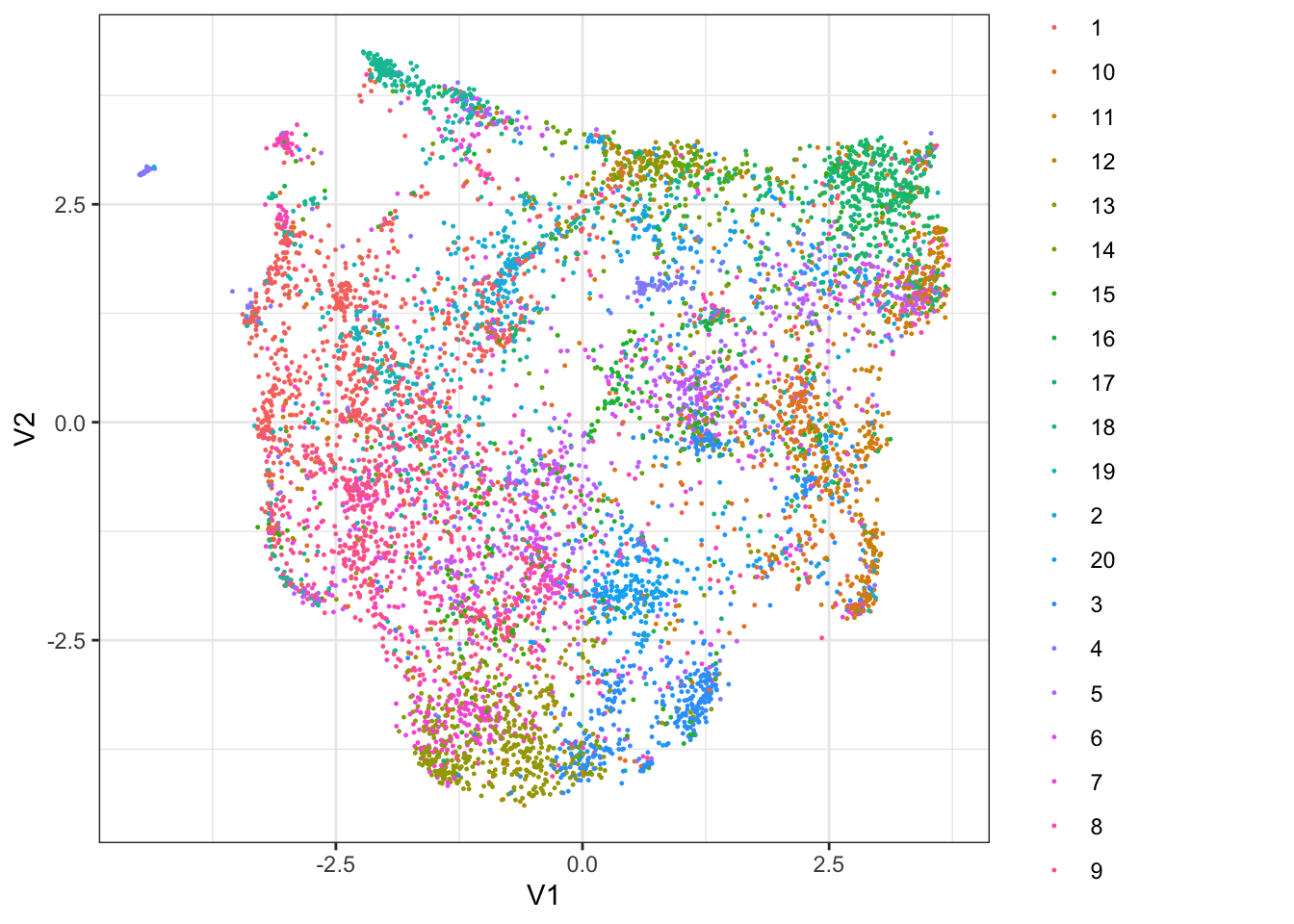
I mange tilfælde matchede klyngerne fra umap emner fra vores topic-model:
Lara Putnam, “The Transnational and the Text-Searchable: Digitized Sources and the Shadows They Cast”, The American Historical Review 121 (2), 2016, s. 337–402 https://doi.org/10.1093/ahr/121.2.377↩︎