Denne artikel beskriver kort, hvilke skridt der blev taget som setup til arbejdet i Transkribus.
Download og håndtering af billedfiler
De originale billedfiler af Aalborgs Stifts Adresseavis – scannet fra mikrofilm – er tilgængelige i Det Kongelige Biblioteks LOAR-repository. Her ligger de samlet i en klump (et “batch”), ligesom resten af avissamlingen indtil 1881.1 De enkelte klumper varierer i størrelse efter principper, der ikke umiddelbart er gennemskuelige. Arbejder man med en anden avis vil man derfor finde avisen delt op i mindre bidder.
Når man downloader og pakker zip-filen ud, finder man en datastruktur, hvor billederne af avissiderne ligger som jp2-filer i individuelle mapper, der hver angiver en enkelt udgave. Hver undermappe indeholder desuden en xml-fil, som vi i denne sammenhæng ikke planlagde at drage nytte af. Altså en ret heftig mængde af undermapper, både med filer, som vi skulle bruge, og nogen som vi ikke skulle. For at kunne importere og navigere i billederne i Transkribus havde vi brug for en anden datastruktur, hvor hvert billede ligger sammen med alle andre i en årgang. I denne struktur er et billedes anknytning til en bestemt udgave anført af navnet på billedfilen. Fordi billedfilerne er navngivet med både avisens titel og udgivelsesdato, havde vi således alt det metadata vi havde brug for, i selve filnavnet.
Første skridt imod en anden struktur var at tage alt hvad, der fandtes i zip-filen og lægge det ind i et R-projekt. Derefter brugte vi det følgende stykke kode til at skabe en ny mappe (“Billeder”), identificere filstien på alle jp2-filer i projektets undermapper og til sidst flytte alle filer, som matchede disse filstier, til den nye “Billeder”-mappe.
Den nye mappe indeholder alle jp2-filer fra undermapperne, der stadig ligger tilbage, men uden billedfilerne. Imidlertid indeholder alle billedfiler ikke reelle tekstdata. Enkelte sider er i den oprindelige affotografering markeret som beskadigede. I sådanne tilfælde er der i sekventiel forbindelse med siden et ekstra billede med et lille forklarende ikon.
Ikoner i den originale indscanning. Det er som regel ikonet med pletten, man støder på.
Vi vurderede, at det var lettest at frasortere disse sider med angivelse af beskadigelse allerede på dette tidspunkt, da det er besværligt at slette individuelle sider i selve Transkribus. Det ville potentielt skabe forvirring i vores endelige datasæt, hvis ikke de blev filtreret fra før benyttelse af layout- og tekstgenkendelsesmodellerne.2 Udskillelsen kunne gøres let ved at sortere filerne i mappen efter størrelse, da disse særlige sider oftest har en mindre filstørrelse end de regulære sider. Filnavnet på billederne, der angiver beskadigede avissider, indeholder desuden tekststrengen “Brik”, så det var en let operation at identificere.
Herefter sorterede vi filerne efter filnavn, hvilket (grundet filnavnstrukturen) betød, at de blev sorteret kronologisk. På dette grundlag delte vi filerne ind i undermapper, der svarede til årgange, så vi senere ville have let ved at navigere til en bestemt årgang i Transkribus.
Konvertering af billedfiler til jpg
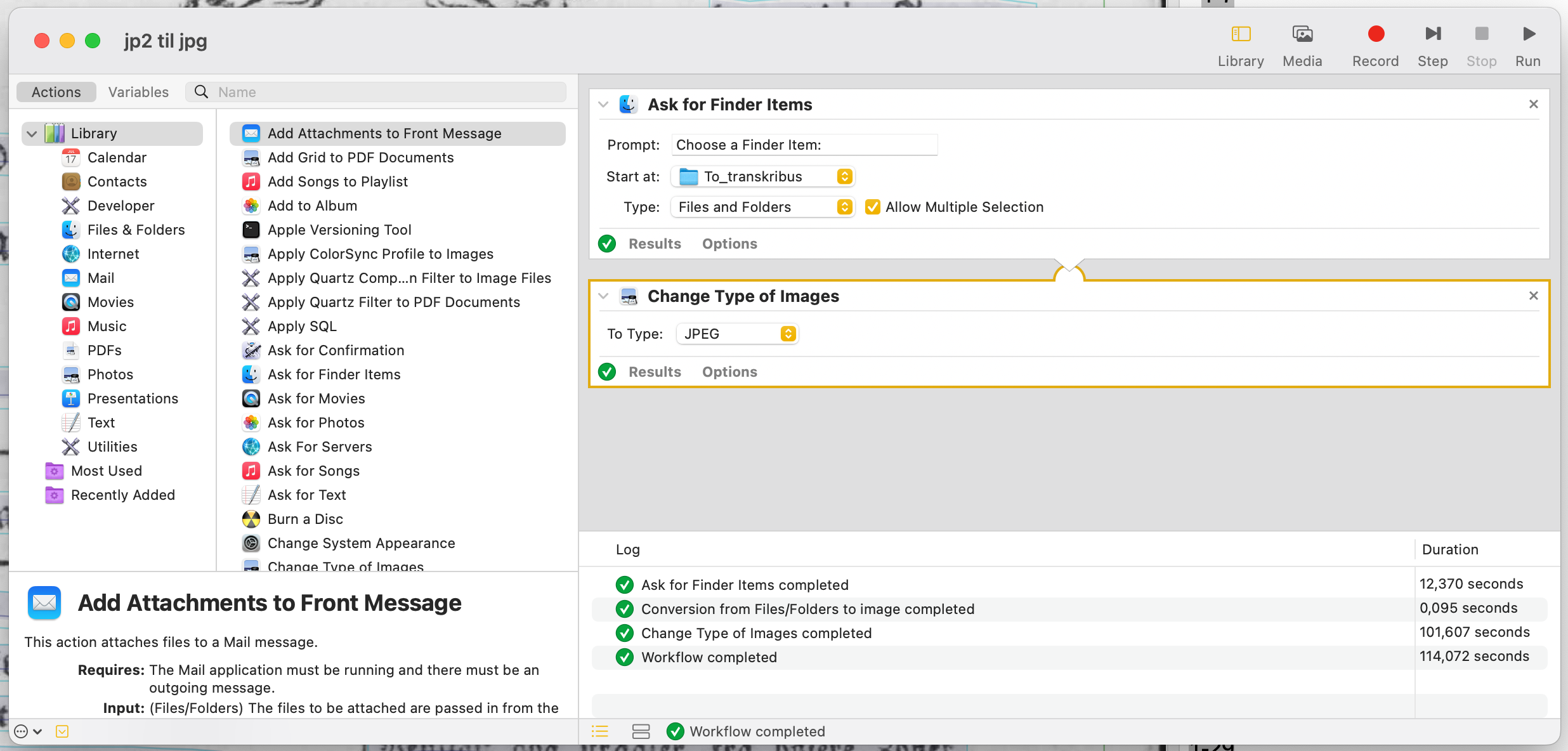
Imidlertid accepterer Transkribus ikke .jp2-formatet. Det var derfor nødvendigt at konvertere billedfilerne til det mere gængse jpg-format. I denne proces blev filerne større. Vi udførte denne konvertering ved hjælp af Automator i macOS.
Konfiguration i Automator.
Imidlertid kunne Automator ikke håndtere alle 6000+ billedfiler, tilsyneladende fordi computeren efter omkring 1000 sider løb tør for RAM. Vi kørte derfor konverteringen en årgang ad gangen.
Upload og setup
Herfra var det simpelt at uploade filerne til Transkribus-serverne i Østrig. Transkribus tillader upload på flere måder - både fra en samlet pdf eller, som her, fra en mappe indeholdende kompatible billedfiler. Selvom Transkribus i begge tilfælde strukturerer hver uploadet enhed som sit eget dokument, beholdes det oprindelige filnavn som et stykke metadata, der siden kan bruges i eksporten af de tekstgenkendte data.
Vi nød godt af høj upload-kapacitet på universitetets internetforbindelse, da filerne på nuværende tidspunkt fyldte betragteligt.
I Transkribus ordnede vi arbejdet ved at skabe en fælles “collection”. Johan Heinsen havde rollen som dennes “owner” imens alle andre projektdeltagere blev føjet til som “editors”. Den primære grund til denne forskel var, at vi fra tidligere vidste, at Transkribus har problemer med at slette dokumenter fra collections med mere end 1 “owner”. Desuden forsikrede det os imod, at en af projektets mindre erfarne Transkribus-brugere ved et uheld skulle komme til at slette dokumenter.
Fodnoter
Royal Danish Library. http://dx.doi.org/10.21994/loar7750. Der er ingen ophavsret på billederne.↩︎
Vi diskuterede kort om dette tab af data var hensigtsmæssigt, men besluttede, at fordi vi altid ville kunne generere en liste over beskadigede sider, var det et fordelagtigt offer.↩︎