Skabelsen af træningsdata
Denne tekst beskriver tilblivelsen af træningsdata til vores layout- og tekstgenkendelsesmodeller. Træningsdata er grundlaget for at træne modeller for at segmentere og tekstgenkende avisen i sin helhed. Dette kræver imidlertid et vist forarbejde. Dette foregik over 3 heldagsworkshops afholdt på Aalborg Stadsarkiv. Vi vil nu forsøge at tage jer med i processen, klik for klik.
Workshop 1: Layout-segmentering
I Transkribus lavede vi et sample af 640 tilfældige avissider. Målet var at inddele disse i tekstregioner baseret på sidernes spalter, samt markere linjerne med tekst. De eksisterende layoutgenkendelsesmodeller, der er tilgængelige i Transkribus har vanskelligt ved at adskille spalter. Men forventningen var, at vi kunne træne en skræddersyet model, der kunne opnå en rimelig præcision. Dette krævede dog en større mængde sider med manuelt segmenterede spalter. Så dem skulle vi lave. Hver deltager fik tildelt 40 sider i vores sample. For at afmystificere processen, finder I nedenfor et forsøg på beskrive arbejdet, klik for klik, så en lignede proces kan foretages af andre. Processen er beskrevet med udgangspunkt i Transkribus online-app.

For at kreere de to tekstregioner brugte vi det manuelle tekstregionsværktøj fra værktøjslinjen, der gør det muligt at tilføje en region med klik. Tekstregionen har i udgangspunktet rette vinkler, men for at få dem til at passe kan trække i dens hjørner og tilpasse således, at den passer med spalten. Dette gjorde vi to gange pr. side. Vi udelod avisens titelrubrik, da denne ikke indeholder noget nyttigt udover datoen – der imidlertid allerede er gemt i filnavnet.
Efterfølgende brugte vi Transkribusmodellen Universal Lines til at foreslå linjer i vores tekstregioner. Ved brug af denne model sørgede vi for, at modellen ikke fandt nye tekstregioner ved at fjerne flueben ved “Find text regions.” Og specificerede, at linjer ikke måtte overskride kanten af en tekstregion ved at sætte flueben ved “Split lines on regions”.
Modellens genkendelse af linjer var i mange tilfælde tilfredsstillende. Enkelte linjer skulle dog tilpasses sådan, at de stemte overens med det skrevne. I nogle tilfælde mødte vi den udfordring at avissiderne var scannet fra en indbundet samling, hvorved marginen trak linjer skæv og i nogle tilfælde slugte ord. Dette resulterede i enkelte tilfælde i, at vores horisontale linjer ikke kunne aflæses. Her blev vi nødt til at hjælpe Transkribus ved at trække i linjerne og i nogle tilfælde indsætte helt nye. Målet var at gøre så meget som muligt læsbart i den senere tekstgenkendelsesproces.

Ved hjælp af den lille pen kan man tilføje nye linjer, og ved at klikke, ganske vist meget præcist, på de i forvejen indsatte blå linjer, er det muligt at tilpasse disse i både længde og retning.
I mange tilfælde havde vi også behov for at samle linjer, der var adskilt. Dette var især tilfældet i slutningen af mange annoncer, hvor selv brødteksten afsluttes og efterfølges af et mellemrum og derefter et navn. Transkribus ordner i udgangspunktet linjer vertikalt, og I nogle tilfælde kan dette betyde, at linjen med navnet på annoncøren skyder sig ind mellem næstsidste og sidste linje, fordi scanningen af siden drejer imod venstre. For at forhindre dette samlede vi derfor disse linjer ved hjælp af merge-funktionen (genvejstasten m).
Med disse skridt bevægede vi os igennem materialet, side for side. Enkelte sider blev i processen markeret som havende et andet layout, f.eks. fordi det indeholdt spalter med tabeller. Disse anomalier forventede vi ville forvirre vores model og de blev derfor ikke taget med.
For at sikre kvaliteten af segmenteringen blev hver side efterfølgende kvalitetskontrolleret af en anden workshopdeltager. Eventuelle tvivlsspørgsmål blev afgjort af Johan Heinsen. Segmenteringen var langsommeligt og ikke specielt inspirerende arbejde. Det var mange linjer, men arbejdet gjorde det muligt for os at igangsætte næste del i processen.
Vi afsluttede første workshop med at sætte træningen af en baselines-model i gang. Vi brugte værktøjets default-settings. Imellem de to workshops kom der dog en række yderligere rettelser, så vi endte med at træne 3 forskellige versioner af modellen. Til den endelige skruede vi op på mængden af træningsepoker.
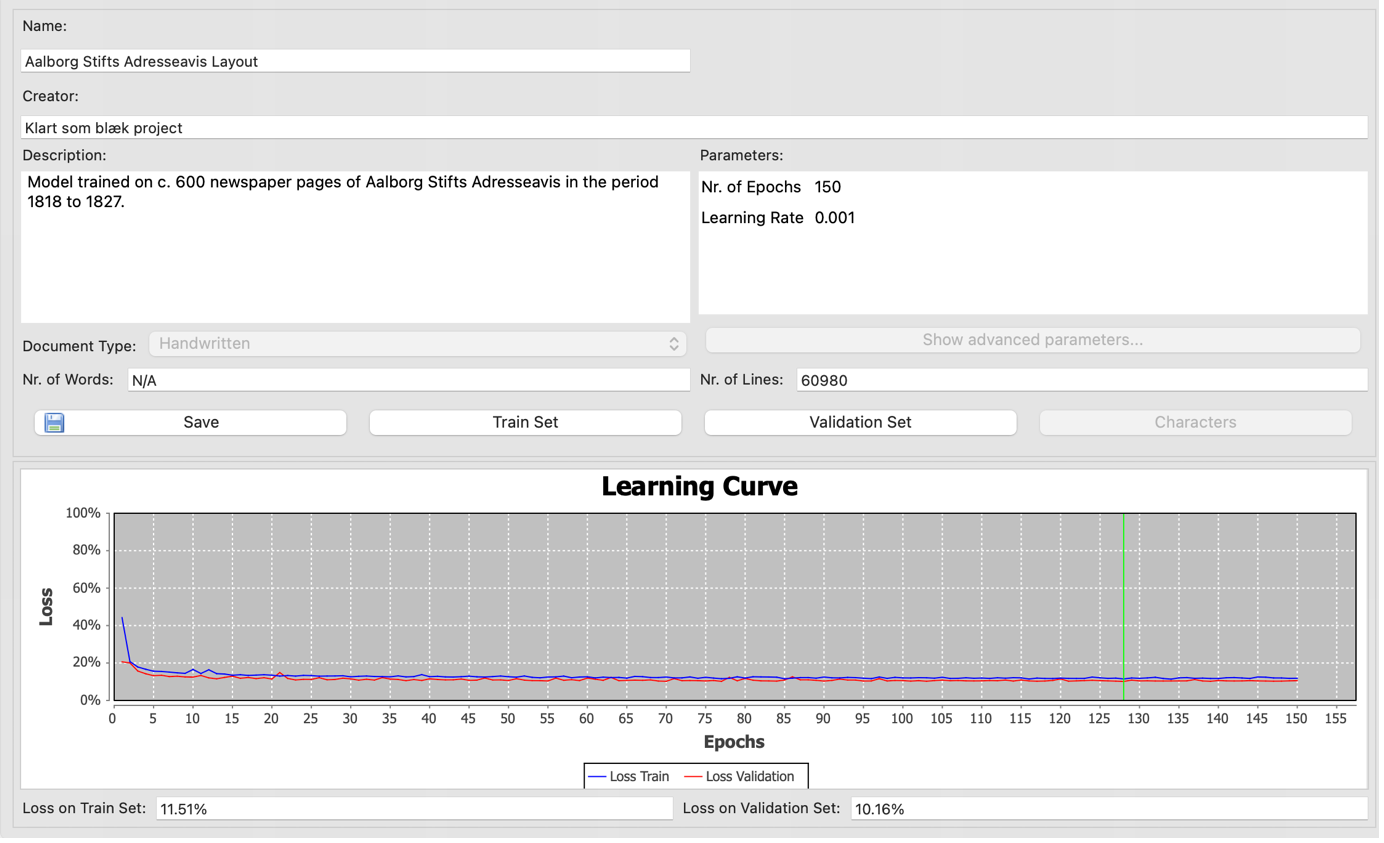
Baselines-modellen performede godt på de regulære sider, men havde problemer, når sider var skæve eller krøllede. Imidlertid foregik arbejdet imens Transkibus nye Fields-værktøj var i beta. Vi prøvede derfor at træne en fields-model. Denne præsterede langt bedre på de mindre regulære sider. I sidste ende var den bedste løsninger derfor at bruge denne model til at genkende regioner, for derefter at bruge vores baselines-model til at genkende linjer.
Ved at klikke på dokumentet, hvori de behandlede avissider i vores sample befandt sig, kunne vi efterfølgende tjekke op på, om Transkribus kunne aflæse de markerede regioner. Vi kunne ligeledes få et overblik over antallet af. Det var et fremragende værktøj, som kan benyttes for at spotte fejlsegmenterede sider, inden den egentlige manuelle transskribering tog fat. For at tilgå disse funktioner, bevægede vi os som beskrevet ind i vores dokument og trykkede derefter på nedenstående ikon, som findes i højre hjørne foroven:

Efterfølgende så vores side sådan ud:
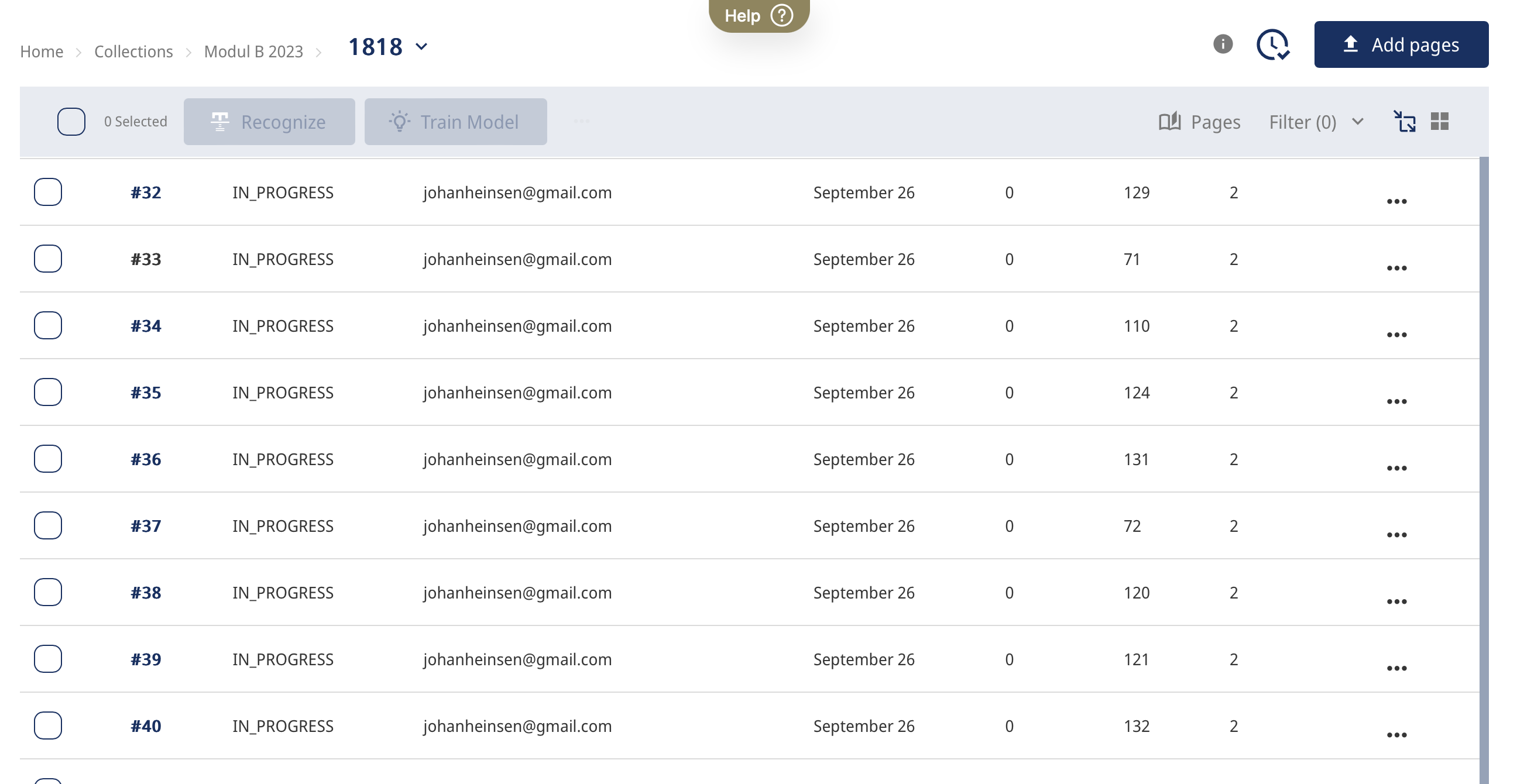
Her var det muligt at se, om siderne indeholdt 2 regioner som forventet. Fields modellen genkendte spaltestrukturen på stort set alle sider. På en del sider måtte spalterne dog manuelt justeres. Dette skete som en del workshop 3.
Med segmenteringen på plads var vi et skridt tættere på at gøre det hele klart som blæk.
Workshop 2: Manuel transkribering
Vi vidste dog, at nu kom det hårde arbejde. For at kunne gøre vores model i stand til at læse den gotiske skrift i aviserne, skulle træningsdata nemlig først transskriberes manuelt. Og ja, det var manuelt! Det var lige så ensformigt som det lyder.
Vi holdt styr på processen ved at udfylde papirslapper med årgang og et sidetal for en given side. På hver lap noterede vi hvem, der havde transkriberet siden og ligeledes, hvem der siden havde korrekturlæst den. Vi kunne nemt have holdt tilsvarende styr på processen med et fælles online-dokument, men papirlapperne betød, at vi slap for at skifte imellem browservinduer undervejs i arbejdet. Samtidig var der tilfredsstillelse i at se bunken med udfyldte lapper vokse.

For at starte transkriberingen af en side, gik vi ind på den side vores papirlap angav og som vi altså havde som opgave at transskribere. Vi havde forinden besluttet at følge Transkribuskonventionen om at bindestreger, der angiver linjeskift tildeles et særligt symbol nemlig symbolet ¬. Symbolet har ikke nogen genvej i web-versionen af Transkribus, men vi knyttede den til vores virtuelle keyboard. Dette fik vi frem med ikonet:

Web-appen har mange fordele, blandt andet, at den kunne køre på næste alle workshopdeltageres computere. Desværre har den et enkelt uheldigt designvalg. Det næste, der skulle gøres for, at det hårde manuelle arbejde blev mindre uhyrligt, var derfor at ændre farven på baseline fra den mørkeblå, der er standardinstilling, til en lysere farve, samt ligeledes skille os af med de talangivelser, som linjerne fremgik noteret med (og som ofte er i vejen for selve linjen). Der var jo i forvejen rigeligt at skulle forholde sig til med aflæsning af perioden gotiske bogstaver og andre stavemåder. Og vi skulle sidde der længe. Derfor kunne vi lige så godt aflaste os selv ved at fjerne noget, som medvirkede til at forvirre øjnene. Det gjorde vi ved at trykke på de små tandhjul nede i hjørnet til højre og ændre på layout settings.
Nu var vi reelt klar til at transskribere linje for linje. Hurra! Men vi blev hurtigt klar over, at enkelte ord ikke var mulige at transskribere, da vi simpelthen ikke kunne tyde de gamle nedskrevne blækklatter. For at undgå et senere problem i vores bearbejdning, og for at opretholde den grad af kvalitet i vores træningsdata, gjorde vi derfor noget andet. Vi blev enige om, at de ord, vi ikke kunne tyde, skulle fjernes. Det er vel den bedste måde at skille sig af med problemer, ikke sandt? Derfor var vi nødt til at benytte en form for fællesbetegnelse, når vi hver især stødte ind i disse problemer. Det magiske ord, som skulle guide os til, hvorvidt det måtte blive eller ej, blev intet mindre spændende end: “[uklart]”. Da man ikke bruger firkantede parenteser i perioden, vil vi senere kunne sortere disse anmærkninger fra. Samtidig taggede vi alle sådanne anmærkninger med strukturtagget “unclear”. Dette gjorde det senere muligt at fjerne alle linjer med noget uklart i forbindelse med træningen af modellen. Vi brugte også dette tag, når vi følte os rimeligt sikre på, hvad der stod, men ikke mente, at der var nok visuel information til at computeren kunne forventes at komme til samme resultat.
Dagen var lang og ret intens. Det krævede stærk kaffe. Vi tog pauser efter behov. Det hjalp på moralen, at der var bagt kage. Den gotiske skrift og periodens sprog var en udfordring for dem, der ikke havde erfaring hermed. Der var stor forskel på, hvor meget materiale de enkelte workshopdeltagere fik arbejdet sig igennem. Men alle bidrag var vigtige.

Bunken med udfyldte papirlapper voksede langsomt men støt, og ved dagens udgang var vi klar til næste del i processen.
Dette var forberedelse til tredje workshop, hvor vi ville transkribere på en anden måde: ikke fra bunden, men ved at korrigere en models gæt. For at gøre dette skulle vi imidlertid bruge en model. Vi satte en træningen af tekstgenkendelsesmodel i gang gennem Transkribus: Expert Client. Herinde skulle der trykkes på “train new model”. Nu kunne vi navngive vores model. Alle modeller skal have angivet et sprog. Fordi vores tekst fremgik på dansk, blev det selvfølgelig dansk, som fik et lille flueben. Sprog skal i denne sammenhæng anses som et stykke metadata, Transkribus kan bruge til at gøre modeller søgbare. Det gav i første omgang ikke mening for os at have en base-model i forhold til vores tekstmodel, hvorfor dette ikke blev valgt. Til gengæld puljede vi vores data med træningsdata fra en anden model trænet på 1700-tals aviser af Johan Heinsen og Camilla Bøgeskov. Dette gjorde vi, fordi vi stadig ikke havde nok træningsdata til, at modellen ville blive tilstrækkeligt robust.
Under den tekniske opsætning inden igangsættelsen af træningen, skulle vi først bestemme et “max-nr. epochs”, som vi satte til 120 således, at modellen ville stoppe igen efter 120 træningsrunder. Efterfølgende satte vi “early stopping” på 20, så vores model ikke ville fortsætte med at køre i al evighed, hvis den ikke forbedrede sig over 20 træningsrunder.
Vi kunne selvfølgelig have fortsat den manuelle transskribering. I stedet valgte vi en proces, der kan virke unødigt kompliceret, men hensigten var at få vores tekstmodel til at arbejde for os, så den i sidste ende kunne spytte noget konkret tekst ud, der kunne speede processen op. Målet hermed var simpelthen at ende med mere træningsdata end hvad manuel transskribering fra bunden havde gjort mulig.
Workshop 3: AI-assisteret transskribering
Transkribus brugte den næste uges tid på at tygge sig gennem vores manuelle transskribering, og til næste workshop stod vi nu med en AI-assistent i form af en prototype af vores model.
Inden vi tog glæderne over resultatet af det hårde arbejde på forskud, forholdt vi os til, hvor stor en mængde fejl, vores model lavede. Modellens fejlrate blev målt procentvis i henholdsvis CER (‘character error rate’) og WER (‘word error rate’). Desto større den procentvise fejlrate var, desto værre ville vores tekstgenkendelsesmodels transskription være. Det kunne betyde, at vi endnu engang skulle bratte ærmerne op og lave samme manuelle arbejde som sidst. Vi holdt alle vejret, da vi klikkede ind for at se modellens fejlrate… Den viste, at vi på nuværende stadie faktisk havde opnået vores ønskede CER på omkring 1%! Vi kunne ånde lettet ud og læne os tilbage for en kort stund. De syv lange timer, hvor alle havde svedt over at gennemskue det gotiske alfabet, havde ikke været forgæves! Den foreløbige model kunne nu være behjælpelig med at transskribere yderligere et sæt af avissider. Med så lav en fejlrate, havde vores manuelle transskribering fra forrige workshop været så udmærket, at vores tekstgenkendelsesmodel kun stod med enkelte fejl i dens transskribering. Selv i sin ufærdige version var modellen blandt de bedste af sin slags. Nu var det så op til alle deltagere at udradere eller i hvert fald nedbringe denne fejlrate, så den kom nærmere 0%. Ambitionsniveauet var højt.
Ligesom sidste workshop, gik vi ind i vores fælles collection på Transkribus, som indeholdt de mange indscannede avissider. Hertil tog vi alle en side hver ligesom sidst, hvor vi var ansvarlige for en transskribering af høj kvalitet, men det føltes som om et mirakel var sket! Ved forrige workshop, stod vi selv for at tyde og transskribere hvert enkelt ord, bogstav for bogstav. Denne gang stod det næsten klart som blæk takket være vores model. Ved mødet med den første side, stod vi nemlig ikke med en tom ramme, ligesom sidst, men i stedet med nedenstående:
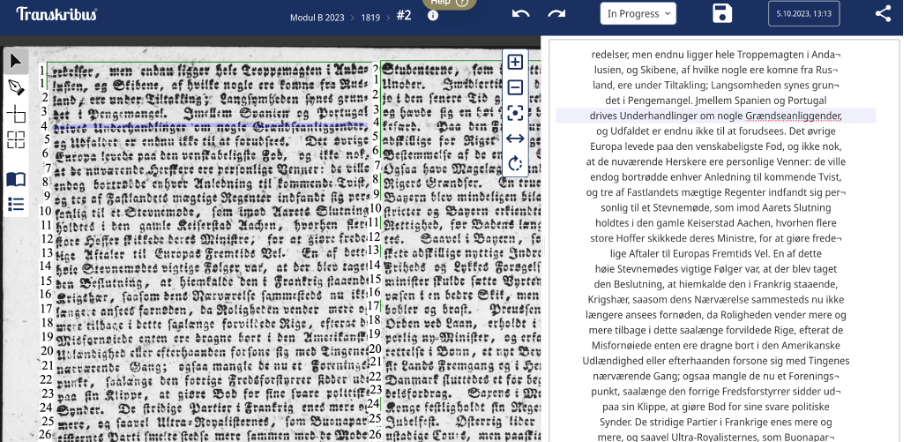
Vi skulle således forholde os til en fuld transskribering af avissidens tekst, og arbejdsbyrden var aftaget betydeligt. Workshoppen forløb derfor således, at vi sad med hver vores avissider og gennemrettede modellens transskriberinger sådan, at vores model kunne trænes med endnu mere træningsdata - og forhåbentlig blive endnu bedre i processen.
Modellen havde enkelte problemer, som vi var særligt opmærksomme på i retteprocessen. Den kunne ikke altid identificere de rigtige tal i brøker. Samtidig var især datoer og årstal ukorrekte, fordi modellen var mere trænet i at genkende specifikke tal end andre. Derudover havde modellen mere lyst til at indsætte punktummer de steder, hvor der egentlig skulle være et udråbstegn, spørgsmålstegn eller citationstegn. Det var med tungen lige i munden, at vi havde særligt øje på netop disse detaljer, der ellers var lette at læse forbi.
For at sikre, at transskriberingen forblev valid, blev siderne ikke kun tilset og rettet én gang, men to gange. Det foregik sådan, at vi på god gammeldags manér havde fysiske sedler i en bunke, hvor vi ligesom ved forrige workshop udfyldte årstallet for avisen, sideangivelse, eventuelle opmærksomhedspunkter samt den ansvarliges navn i første runde af gennemtjek. Efterfølgende tog en ny deltager samme seddel og foretog anden runde af gennemtjek, som efter samme kyndige hånd kunne skrive under. Den endelige avisside var således transskriberet ved hjælp af vores tekstgenkendelsesmodel og to deltagere. Så blev det ikke mere klart som blæk! Trods den analoge fremgangsmåde, skal man ikke underkende effektiviteten, for bunken med sedler voksede denne gang hurtigt. Om det skyldtes den nu allerede udmærkede oversættelsesmodel eller deltagernes engagement vides ikke. Vi antager, at det var en god blanding af begge dele.
Når en seddel fik underskrift nr. 2, var det altafgørende, at vi i Transkribus noterede avissiden som “ground truth” (eller Transkribus’ danske oversættelse: “sandhed på jorden”). Så var arbejdet gemt korrekt, og de rettede sider lette at finde, når de senere skulle bruges som træningsmateriale.

Dagens workshop sluttede som den forrige: vi igangsatte træningen af første version af det, som skulle blive vores endelige model.