Aalborgs Stifts Adresseavis og Avertissementstidende
Link til fritekstsøgning: https://hislabaau.shinyapps.io/aalborg_1818/
Udgivelsessted: Aalborg
Periode dækket: 1818-1827
Digitaliseret: September 2023 - Januar 2024
Digitaliseret af: Johan Heinsen, Laura Aagaard, Rasmus Due Bak, Mads Lehrmann Christensen, Mie Dodensig, Dionysia Horne, Maja Stecher Jensen, Ravn Jørgensen, André Sigaard Mikkelsen, Caisa Johanna Ingerslev Nedergaard, Frederik Sørig Søndergaard Nielsen, Christian Friis Olesen, Fiona Gesine Otten, Anne Katrine Holm Pedersen, Maja Sjørslev Petersen, Louise Haldrup Riske, Zenia Skytte Sørensen, Maja Kromann Sørensen, Jeppe Risager Ubbesen
Projektet blev oprindeligt udført som et særskilt projekt i regi af modul B på kandidatuddannelsen i Historie ved AAU. Du kan læse meget mere om projektet og datasættets tilblivelse her: https://hislab.quarto.pub/aalborgonline/
Billedproveniens: LOAR
Version: 1.0
Præcision af tekstgenkendelse
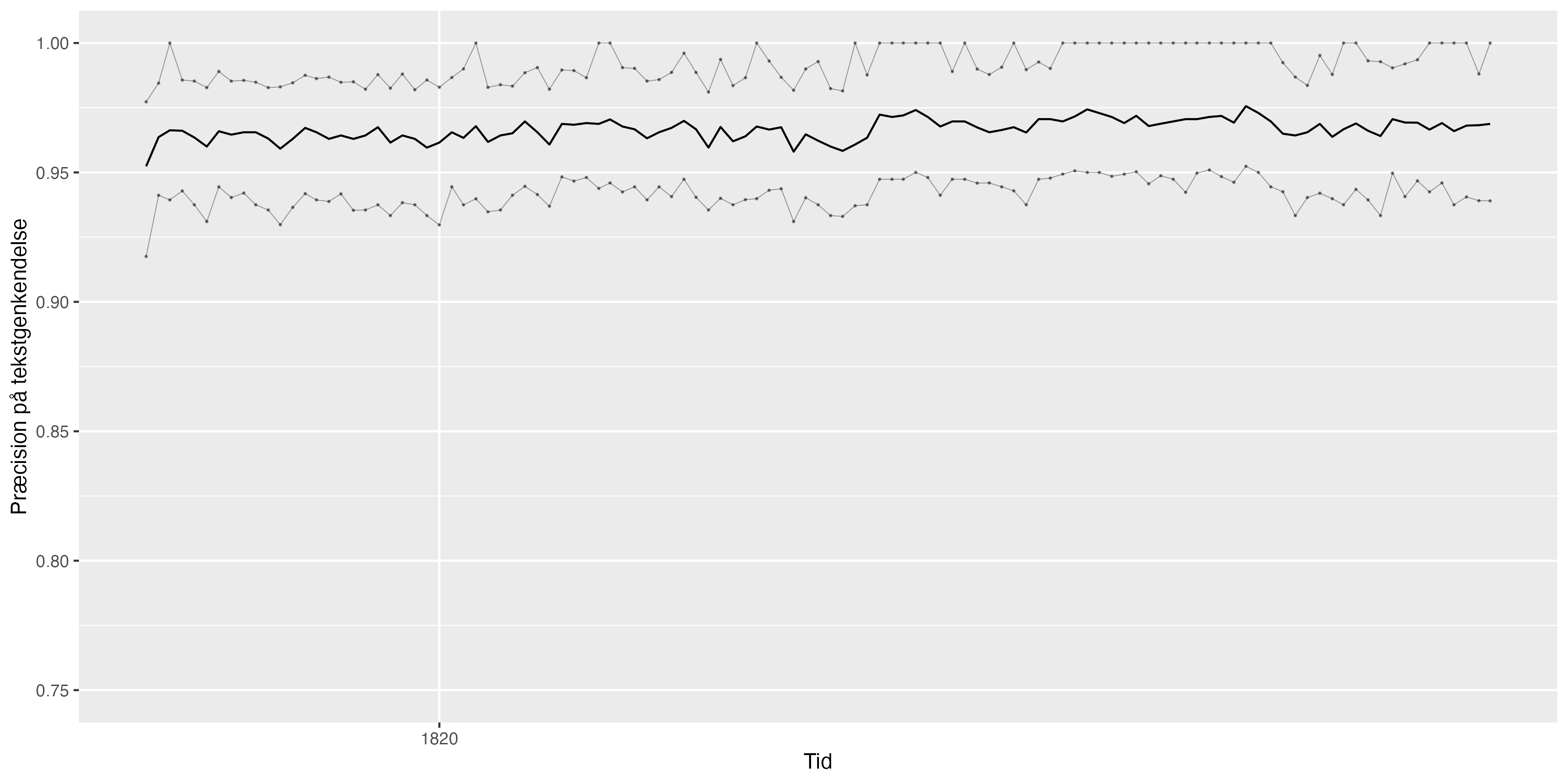
Kendte udfordringer, der forårsager ujævn præcision:
- I årgangene 1821-22 gør indbindingen, at ikke hele venstre spalte er synlig.
Forklaring af datasættets kolonner
text: Indeholder den identificerede tekst. Teksten er segmenteret. Algoritmen er designet til at transkribere bogstavret og tekstsøgninger skal indrettes derefter. Det er denne variabel, der søges i via søgeknappen. Søgefeltet godtager regex.
id: Dette er et unikt id for den givne tekst. Vær opmærksom på, at disse id’er opdateres for hver udgave af datasættet.
dato: Datoen for udgivelsen i formatet år-måned-dag. Du kan klikke på datoen og læse hele udgaven for den givne dato.
pwa (= predicted word accuracy): Denne kolonne indeholder en beregnet score for præcisionen på tekstgenkendelsen. Værdierne rangerer mellem 0 og 1.
vis lignende tekster: Her har du mulighed for en alternativ filtrering, der viser en given teksts 25 nærmeste slægtninge i avisen. Slægtskabet er udregnet på baggrund af teksternes placering i et semantisk rum skabt via en encoder-model (https://huggingface.co/JohanHeinsen/Old_News_Segmentation_SBERT_V0.1) og Facebook Artificial Intelligence Similarity Search (https://faiss.ai/index.html).
link: her kan du gå til den oprindelige affotografering, der er tilgængelig i Mediestream.