Dokumentation
Hvordan har vi gjort? Nedenfor beskriver vi vores workflow og de modeller, vi har skabt til bearbejdningen. Det er beskrevet trin for trin.
Fejl nedarves igennem processen. Selv en lille fejlrate på et trin kan blive til et stort problem, hvis det udfordrer den senere bearbejdning. Et grundlæggende princip bag designet er derfor, at processen kan gøres igen og igen, når vi ønsker at udbedre en fejl.
Materialets ophav
Langt størstedelen af materialet i ENO stammer fra Det Kongelige Bibliotek. Vi har benyttet de mikrofilmede affotograferinger tilgængeliggjort via LOAR. Selve avissamlingen er tilgængelig her https://loar.kb.dk/collections/3933596a-95ca-4927-b55c-3ba948ea6603.
Før videre bearbejdning er billedfilerne konverteret fra .jp2 til .jpg. Herefter er de uploadet i Transkribus i separate årgange. Metadata om udgivelse og dato er bevaret via filnavnet. Det norske materiale fra Nettbiblioteket kræver ikke tilsvarende konvertering. Det har tilsvarende metadata indlejret i filnavnet.
Følgende aviser findes i version 1.0:
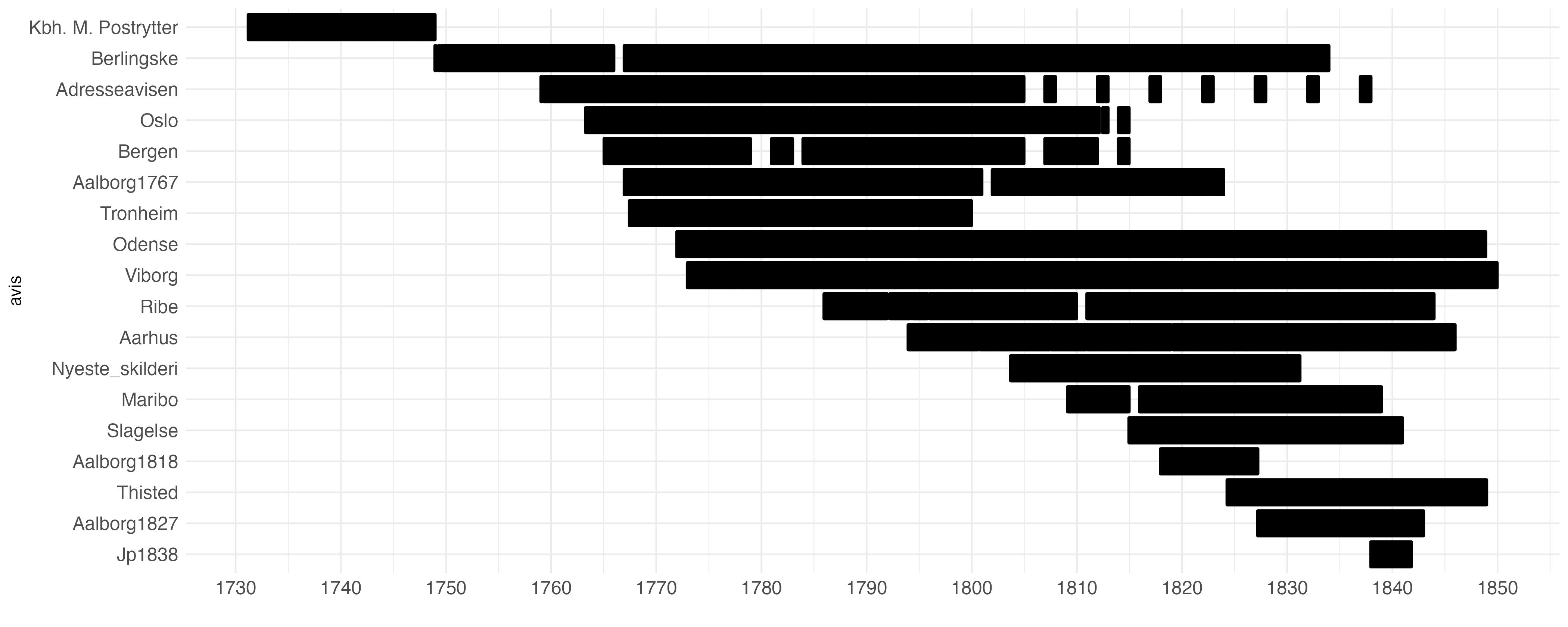
Materialets fordeling over tid afslører, at datasættet dækker perioden fra 1775 langt bedre end tiden forinden.

Bearbejdning i Transkribus
Processen i Transkribus består af 3 skridt.
Spaltestrukturen er første udfordring. Hvis tekstgenkendelsesmodeller køres uden nogen videre forberedelse forstyrres rækkefølgen på linjer ofte ved, at sidernes spalter flyder sammen. Derfor er spaltesegmentering afgørende for et brugbart output. Vi har løst problemet på forskellige måder. I de første faser af projektet benyttede vi skrædersyede baselines-modeller, men disse lavede fortsat en del fejl og mange sider måtte justeres manuelt. Især aviser med snæver afstand imellem spalter var vanskelige med dette workflow. Fra og med efteråret 2023 har vi benyttet Transkribus’ field-modeller til formålet. Disse segmenterer et billede med tekst i separate tekstregioner.1
Vi har en grundmodel, der benyttes, hvis layoutet fremstår uproblematisk. Forudser vi særlige udfordringer med en given avis (atypiske visuelle elementer), træner vi særlige modeller med træningsmaterialet fra grundmodellen, men med ekstra materiale fra den problematiske avis. Resultatet er en layoutgenkendelse med høj præcision. Usædvanlige sider kan dog fortsat indeholde fejl og overlappende tekstregioner er et tilbagevendende problem, hvis de visuelle elementer, der adskiller tekster er udviskede. Tekstregionerne sorteres efterfølgende kolonnevis, da dette typisk giver det korrekte tekstflow.Genkendelsen af linjer er lettere. Her benytter vi i udgangspunktet Transkribus’ egen Universal Lines model, der i de fleste tilfælde præsterer bedre, end de modeller vi selv har forsøgt at skabe. Fordi vores materiale allerede er spaltesegmenteret splittes alle linjer på tekstregionernes grænser. Dermed undgår vi linjer, der går på tværs af layoutelementer. Det væsentligste tilbageblivende problem er identifikationen af ikke-eksisterende linjer, når blæk fra næste side er blødt igennem papiret. Disse optræder i datasættet som linjer af tekst, der ikke giver nogen mening.
Tekstgenkendelsen foretages med en pylaia-model skabt specifikt til formålet. Modellen er tilgængelig via Transkribus under navnet Danish Newspapers 1750-1850. Den er trænet på omkring 420.000 håndtranskriberede ord. På sine valideringsdata præsterer modellen en fejlrate på tegnniveau (CER - character error rate) på 0.56%. I praksis er præcisionen typisk lidt ringere. Modellen er skabt med hjælp fra studerende på Aalborg Universitet. Du kan læse mere om dens tilblivelse på https://hislab.quarto.pub/step_2.html. Enkelte aviser er tekstgenkendt med særskilte modeller, der er modificeret for at løse konkrete problemer (f.eks. særlige typer til overskrifter, gnidrede sider etc.).
Segmentering i enkelte artikler
Fra start var en af ambitionerne med projektet at kunne lave datasæt til kvantitativ tekstanalyse. Dette besværliggøres dog af, at en avisside kan indeholde mange enkelte tekster, ligesom en enkelt tekst kan løbe på tværs af sider. Derfor er det nødvendigt at segmentere det tekstgenkendte output yderligere. Dette arbejde er sket i R og Python.
Vi valgte at bearbejde siderne i deres simpleste form, nemlig som rå .txt-filer. Dette valg traf vi, fordi avisernes layout er så heterogent, at det på tværs af korpus er svært at udlede noget meningsfuldt om tekststruktur på baggrund af en linjes placering på siden. Derfor tager vi udgangspunkt i et format, hvor hvert billede bliver eksporteret fra Trankribus som et .txt. Fordi filnavnene indeholder metadata om dato, ved vi stadig, hvilke sider, der hører til hinanden og i hvilken rækkefølge.
Det enkelte tekstdokument består af linjer.2 Deres rækkefølge er dikteret af den sortering vi har lavet på tekst-regioner. Det ser f.eks. sådan ud:

Vi eksperimentede med en række forskellige teknikker, men er endt med et workflow, der var formet af følgende prioriteter:
Workflowet er hurtigt, så det kan gøres igen, hvis vi f.eks. retter i teksten i Transkribus.
Workflowet er ikke afhængigt af eksterne tjenester eller tung computation f.eks. grundet decoder-modeller.
Workflowet koster ikke noget at køre.
Workflowet har et rimeligt energiaftryk.
Især fravalget af store decodermodeller var afgørende, da disse kan lette opgaven, men er omkostningsfulde at benytte - uanset om de kører lokalt eller via api. Løsningen blev i stedet at skabe en BERT-model trænet på materialet. Her fik vi assistance fra CALDISS. Grundmodellen er beskrevet her: https://huggingface.co/CALDISS-AAU/DA-BERT_Old_News_V1. Det er en fill-mask model trænet på c. 250 millioner ord. Den er grundlaget for en model trænet specifikt til at håndtere segmenteringsopgaven, der findes her: https://huggingface.co/JohanHeinsen/Old_News_Segmentation_SBERT_V0.1. Træningsmaterialet for denne version er et sample på c. 30.000 håndtaggede linjer, der er annoteret således, at det angives, hvis en linje udgør starten på en ny tekst. Fintuningen roterer om at modellen lærer at se lighed mellem sætninger fra en given tekst og forskel imellem disse sætninger og sætninger fra andre tekster.
På baggrund af denne fintuning har vi trænet 3 setfit-modeller, der klassificerer linjer.3 De er trænet på samme træningsmateriale som segmenteringsmodellen. De 3 modeller forudsiger henholdsvis:
Er en linje en overskrift?4
Er en linje første linje i en tekst? (ikke alle tekster har overskrifter)5
Er en linje sidste linje i en tekst?6
Vi benytter os af modellens angivelse af sandsynlighed. Fordi vi kender linjernes flow kender vi for hver linje også de tre modellers sandsynlighedsberegninger for den foregående og efterfølgende linje. Tilsammen danner disse prædiktioner af sandsynlighed (for linjen og dens naboer) grundlag for en random forest model, der endeligt tager stilling til, om rækken af linjer skal splittes på en given linje - hvorved en ny tekst kommer til at starte der. Udover ovennævnte sandsynligheder benytter modellen også en række strukturelle elementer ved linjerne til denne opgave: Disse inkluderer: antallet af hhv. bogstaver, tal og grammatiske tegn, hvorvidt sidste tegn er punktum, hvorvidt linjen indeholder et af en række hyppigt forekommende personnavne, hvorvidt linjen indeholder en dato, hvorvidt linjen omtaler et sted defineret af en manuelt etableret liste af steder, hvorvidt linjen forinden er kortere end 40 tegn, hvorvidt linjen starter med et stort bogstav, samt en angivelse af, hvor i en given udgave linjen optræder (fra 0, hvis linjen er udgavens første linje. til 1, hvis det er den sidste). På baggrund af alle disse elementer splittes udgaven så i mindre stumper.
Den endelige model har en f1-score på 98.9. Det er højt, men langtfra perfekt. Problemet med segmenteringen er nemlig, at chancen for at gætte forkert eksisterer på hver eneste linje. Derfor er segmenteringen af de enkelte tekster i praksis måske datasættets svageste led.
Modellen præsterer bedst på aviser fra 1800-tallet, hvor rubrikstrukturer bliver mere gennemgående, og på tekster med en høj grad af standardisering - f.eks. annoncetyper, der kommer igen og igen. Det er også mere sandsynligt, at en kort tekst er korrekt segmenteret end en lang. Elementer som initialer eller illustrationer udfordrer modellen som en nedarvet fejl fra linjesegmenteringen.
Fordi modellen ofte splitter overskrifter fra deres brødtekst, har vi efterfølgende kollapset tekstpar, hvis første tekst var på mindre end 45 tegn og har en beregnet sandsynlighed på mindst 0.75, i forhold til om den er en overskrift. Alligevel findes der mange steder i datasættet overskrifter, der fremstår som separate tekster adskilt fra deres brødtekst. Hjemløse overskrifter.
Vi planlægger at træne en ny version af BERT-modellen samt de afledte segmenteringsmodeller i anden halvdel af 2025. Håbet er, at vi kan fange et positivt feedback-loop, hvor den nuværende segmentering kan være grundlag for en bedre model, der så kan skabe endnu bedre segmentering.
Metadatering
I version 1.0 ledsages hver tekst af 3 elementer af metadatering: dato, pwa og lignende tekster.
Datoen er udledt direkte fra filnavnet, når materialet kommer fra LOAR eller Nettbiblioteket. Hvor materialet har en anden proveniens, er datoen identificeret enten manuelt eller ved hjælp af regex, sidstnævnte giver fejl f.eks. i avisen Nyeste Skilderie af Kiøbenhavn.
Pwa står for predicted word accuracy. Her scores hver tekst med en beregning for præcisionen af tekstgenkendelsen. Fremgangsmåden er simpel: hver tekst tokeniseres i ord, der så holdes op imod en ordbog af ord, der eksisterer i materialer fra perioden. Hvis et ord ikke findes i denne ordbog, er det typisk fordi, det faktisk ikke fandtes i den historiske virkelighed og i stedet er et produkt af fejl i tekstgenkendelsesprocessen. Sjældne egennavne kan dog også risikere at blive identificeret som fejl, fordi de ikke optræder i ordbogen. Samtidig kan ord, der er genkendt forkert, godt være genkendt som et eksisterende ord. Derfor er pwa vejledende. Vi har dog vurderet at den er nyttig, f.eks. hvis materialet skal benyttes til sprogmodellering. Tekster på andre sprog end dansk har typisk også en lavere pwa, end danske tekster, hvorved det bliver muligt at filtrere dem fra.
Ordbogen er skabt til formålet og består af unikke ord, der findes i dansk kanonlitteratur fra perioden. Denne litteratur er udvalgt fra https://huggingface.co/datasets/danish-foundation-models/danish-dynaword/blob/main/data/adl/adl.md. Dertil er føjet en liste over ord, der optræder i Grundtvigs forfatterskab stillet til rådighed af Center for Grundtvigforskning, Aarhus Universitet. Vi har ligeledes tilføjet gentagne person- og stednavne fra folketællingen i 1787. Endelig er tilføjet en manuelt filtreret liste af de 10.000 mest hyppige ord i ENO, der ikke findes i de to førnævnte datasæt.7
Lignende tekster er udregnet ved at skabe en embedding af hver tekst ved hjælp af segmenteringsmodellen (https://huggingface.co/JohanHeinsen/Old_News_Segmentation_SBERT_V0.1). Af hensyn til omkostningen i computation har vi valgt ikke at udregne lighed imellem alle tekster i en given avis, men benytter i stedet Facebook Artificial Intelligence Similarity Search (FAISS) til at skabe et indeks (IndexFlatIP) på baggrund af teksternes vektorrepræsentation. Vi bruger dette indeks til at finde 100 kandidater til slægtninge for hver tekst.8 Fra denne liste udpeger vi ved hjælp af cosinus-lighed de 25 nærmeste slægtninge, der gemmes i en liste. Dermed bliver det muligt at bevæge sig horisontalt gennem materialet, der nu kan forstås som en graf.
Senest opdateret 4 august 2025.
Fodnoter
Vi benytter ikke fields-modellernes mulighed for automatiseret tagging.↩︎
På dette tidspunkt laver vi desuden et simpelt regelbaseret træk, for at imødekomme fejlagtige sammentrækninger af ord. Ofte er Transkribus-linjemodellen nærig og afslutter linjen et par pixels for tidligt. Det betyder, at der er lidt flere fejl i slutningen af linjer, end der ellers burde. Lagt sammen med det faktum, at orddelinger typisk er markeret ved små tegn, der hurtigt udviskes er der en tilbøjelighed til, at tekstgenkendelsesmodellen ser bindestreger, der ikke findes i slutningen af linjen. Ovenfor ses et eksempel med frasen “Valentins ordre”, hvor tekstgenkendelsesmodellen har tilføjet et ¬ (som er kodningen af bindestreger ved linjeskift i Transkribus). Vi kan omgå en del af disse fejl ved at tjekke alle ord, der skabes når ord sammentrækkes af bindestreger på tværs af linjer. Det gør vi ved, at måle dem op imod en ordliste, med ord, der findes (denne liste beskrives under “pwa” senere). Hvis det sammentrukne ord ikke findes på listen, men de to dele hver især gør, fjernes bindestregen og dermed splittes de.↩︎
Setfit-arkitekturen er beskrevet her: https://github.com/huggingface/setfit.↩︎
F.eks. indeholder aviserne en del juridisk proklama, hvis vokabular er fraværende i litteraturen.↩︎
https://engineering.fb.com/2017/03/29/data-infrastructure/faiss-a-library-for-efficient-similarity-search/↩︎