Norske Intelligenssedler
Link til fritekstsøgning: https://hislabaau.shinyapps.io/oslo/
Udgivelsessted: Oslo
Periode dækket: 1763-1814
Fraværende årgange: 1813
Digitaliseret: September 2024 - Juni 2025
Digitaliseret af: Johan Heinsen
Billedproveniens: Nettbiblioteket
Version: 1.0
Præcision af tekstgenkendelse
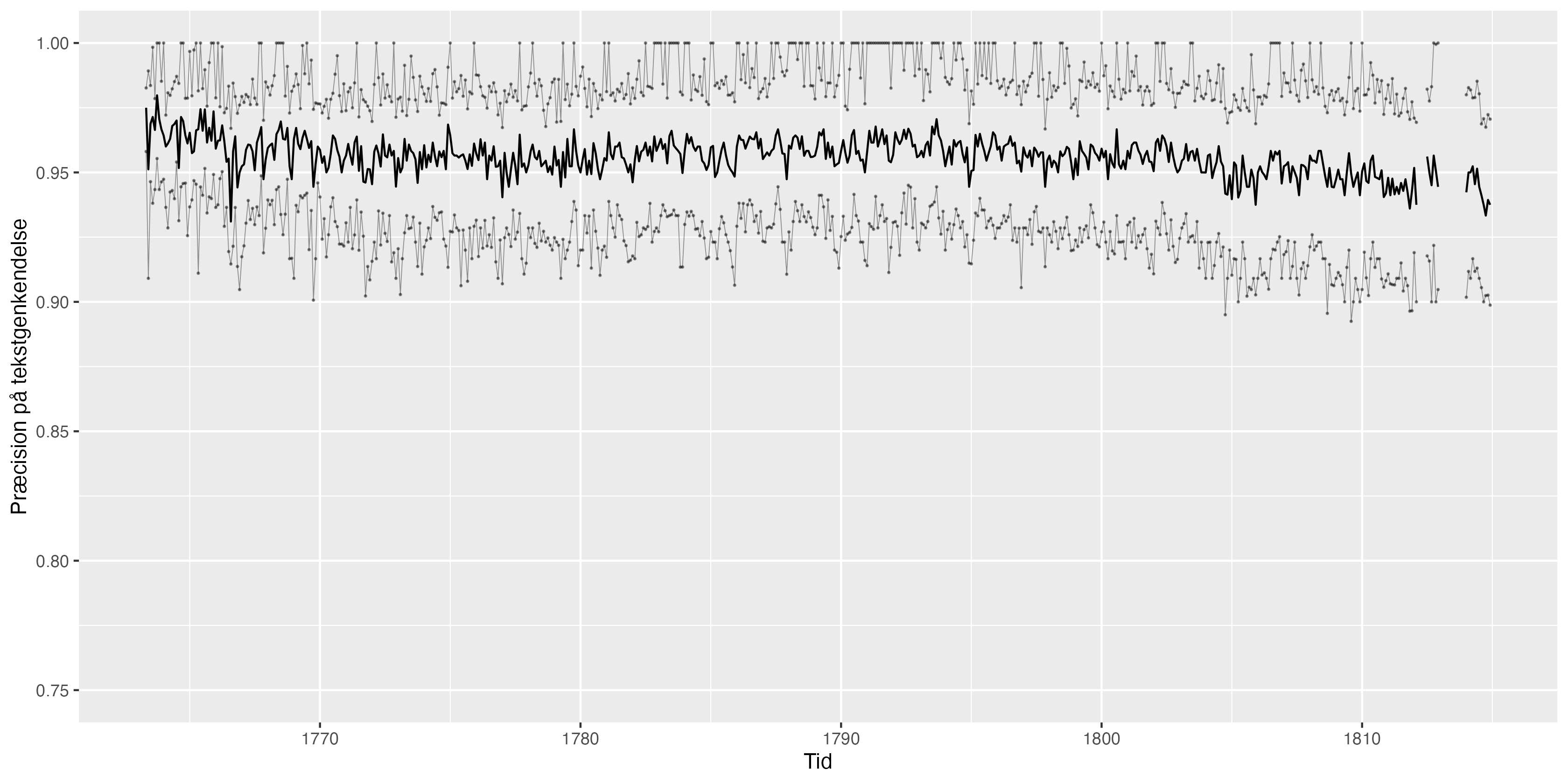
Kendte udfordringer, der forårsager ujævn præcision:
Avisen er digitaliseret fra højkvalitetsfotos. Tekstgenkendelsesmodellen er ikke tunet til så gode fotos og har derfor udfordringer, især med overskrifter.
Avisen indeholder en del annoncer sat med antigua-typer. Tekstgenkendelsen er her lavere, da modellen er trænet til fraktur.
Forklaring af datasættets kolonner
text: Indeholder den identificerede tekst. Teksten er segmenteret. Algoritmen er designet til at transkribere bogstavret og tekstsøgninger skal indrettes derefter. Det er denne variabel, der søges i via søgeknappen. Søgefeltet godtager regex.
id: Dette er et unikt id for den givne tekst. Vær opmærksom på, at disse id’er opdateres for hver udgave af datasættet.
dato: Datoen for udgivelsen i formatet år-måned-dag. Du kan klikke på datoen og læse hele udgaven for den givne dato.
pwa (= predicted word accuracy): Denne kolonne indeholder en beregnet score for præcisionen på tekstgenkendelsen. Værdierne rangerer mellem 0 og 1.
vis_lignende: Her har du mulighed for en alternativ filtrering, der viser en given teksts 25 nærmeste slægtninge i avisen. Slægtskabet er udregnet på baggrund af teksternes placering i et semantisk rum skabt via en encoder-model (https://huggingface.co/JohanHeinsen/Old_News_Segmentation_SBERT_V0.1) og Facebook Artificial Intelligence Similarity Search (https://faiss.ai/index.html).